@senspond
>
정보검색(IR) 개요 - 색인(Index), 역색인(Inverted Index) 에 대해서 알아봅시다
검색엔진
이 글은 색인과 역색인, 그리고 정보검색(IR) 개요에 대해서 정리해본 글입니다.
색인(Index)과 역색인(Inverted Index)
색인(Index)란? 🍎
먼저 색인의 사전적 정의는 다음과 같습니다.
색인(索引)은 책 속의 낱말이나 구절, 또 이에 관련한 지시자를 찾아보기 쉽도록 일정한 순서로 나열한 목록을 가리킨다.인덱스(index)라고도 한다.
즉, Index는 데이터를 찾기 위한 참조용 목록 데이터라고 할 수 있습니다.

RDMS 중심의 백엔드 개발을 하다보면 SQL 실행계획을 보면서 오래걸리는 쿼리들을 튜닝해가면서 효율적인 인덱스를 타게 하게끔 많은 시간을 보내기도 하는데요.
역색인(Inverted Index) 을 다루기 앞서 먼저 전통적인 RDMS에서의 색인(Index)에 대해서 알아봅시다.
RDMS 에서의 인덱스(Index)
대표적인 데이터베이스인 오라클(Oracle)과 Postgresql 은 기본적으로 B-Tree(Balanced Tree) 구조로 인덱스를 생성합니다.
B-Tree는 자식 2개 만을 갖는 이진 트리(Binary Tree)를 확장하여 N개의 자식을 가질 수 있도록 고안된 것이다.
그리고 좌우 자식 간의 균형이 맞지 않을 경우에는 매우 비효율적이라, 항상 균형을 맞춘다는 의미에서 균형 트리(Balanced Tree)라고 불린다.
B-Tree는 최상위에 단 하나의 노드 만이 존재하는데, 이를 루트 노드(Root Node)라고 한다. 그리고 중간 노드를 브랜치 노드(Branch Node), 최하위 노드를 리프 노드(Leaf Node)라고 한다.
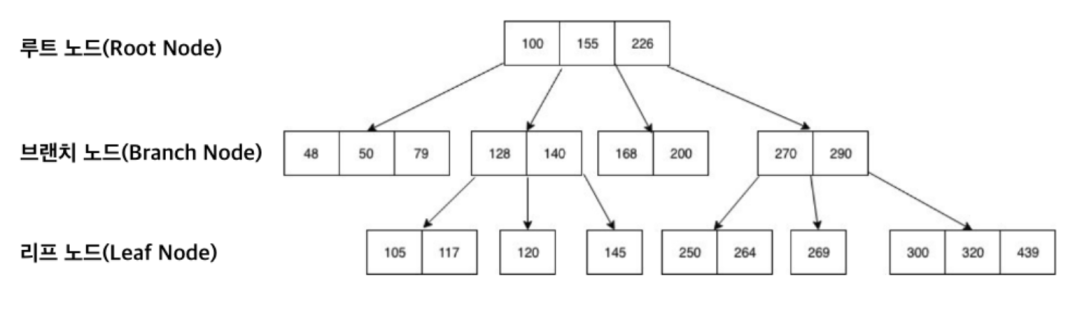
B-Tree는 위처럼 노드 하나에 여러 데이터가 저장될 수 있다. 각 노드 내 데이터들은 항상 정렬된 상태이며, 데이터와 데이터 사이의 범위를 이용하여 자식 노드를 가진다. 그러므로 자식 노드 개수는 (n+1)을 가진다.
위 두 개의 트리는 항상 좌, 우 자식노드 개수의 밸런스를 유지하므로 🍎 최악의 경우에도 무조건 탐색 시간이 O(logN)을 가지게 된다. 🍎 RDMS에서 기본적인 인덱스로 채택되는 이유라고도 할 수 있음
그런데 RDMS에서는 방대한 데이터에서 특정 키워드로 LIKE 검색을 하게 될때 문제가 하나 있습니다.
SELECT * FROM BLOG
WHERE body LIKE '%자료구조%'전통적인 인덱스로는 자료를 빠르게 탐색할 수 있는 방법이 전무하며 모든 레코드를 풀 스캔해가며 일일히 body에서 뒤져야 합니다.
따라서, 자료가 방대해지면 방대해 질 수록 쿼리비용이 굉장히 높아지게 됩니다.
하지만, 최근 MySql / Postgresql 에서는 단어/구문 검색을 위해서 전문검색(FullText Index)를 지원합니다.
postgresql은 전문 검색을 지원하도록 고안된 두 가지 데이터 유형을 제공하는데, tsvector 유형은 텍스트 검색에 최적화된 형식의 문서를 나타내고 tsquery 유형은 텍스트 쿼리를 유사하게 나타냅니다.
postgresql 은 직접 검색어사전을 구성하고 원하는 키워드만을 색인 시킬 수가 있습니다만, 간단하게 사용하기에는 mysql 쪽이 훨씬 쉽고 간편합니다.
굳이 검색엔진까지 구축해서 사용할 필요가 없는 경우에 간단하게 사용할만 합니다.
Full-text Search 검색 쿼리 (Mysql 5.7 이상)
사용예 )
CREATE FULLTEXT INDEX BLOG_SEARCH_IDX ON BLOG(body) WITH PARSER ngram; SELECT * FROM BLOG WHERE MATCH(body) AGAINST("자료구조")
검색 방식
자연어 검색(natural search):
검색 문자열을 단어 단위로 분리한 후, 해당 단어 중 하나라도 포함되는 행을 찾는다.
불린 모드 검색(boolean mode search)
검색 문자열을 단어 단위로 분리한 후, 해당 단어가 포함되는 행을 찾는 규칙을 추가적으로 적용하여 해당 규칙에 매칭되는 행을 찾는다.
쿼리 확장 검색(query extension search)
2단계에 걸쳐서 검색을 수행한다. 첫 단계에서는 자연어 검색을 수행한 후, 첫 번째 검색의 결과에 매칭된 행을 기반으로 검색 문자열을 재구성하여 두 번째 검색을 수행한다. 이는 1단계 검색에서 사용한 단어와 연관성이 있는 단어가 1단계 검색에 매칭된 결과에 나타난다는 가정을 전제로 한다.
토크나이저 / 파서(Parser)
Stop-word parser
공백을 구분자로 단어 단위로 저장을 하기 때문에 검색하는 단어가 정확히 일치해야지만 결과를 받을 수 있다. "자료 구조"가 검색이 안됨. 기본값 N-gram에 비해 좀더 빠른 검색속도
N-gram Parser
ngram 파서는 일련의 텍스트를 n개의 문자로 구성된 연속된 시퀀스로 토큰화합니다.
예를 들어, n그램 전체 텍스트 파서를 사용하여 n의 다른 값에 대해 "abcd"를 토큰화할 수 있습니다.
n=1: 'a', 'b', 'c', 'd' n=2: 'ab', 'bc', 'cd' n=3: 'abc', 'bcd' n=4: 'abcd'"자료구조"로 검색시 "자료 구조"가 검색이 됨
파서(토크나이저)를 통해 문서에서 토큰을 추출하고 해당토큰이 존재하는 레코드들의 식별자들을 기록해 둡니다.
검색쿼리를 실행할때 해당 목록을 먼저 참조함으로써 레코드를 풀스캔 하지 않고 빠르게 검색이 가능한 방식이죠.
사실 이 원리는 다음에 설명할 역색인(Inverted index) 이기도 합니다.
역색인(Inverted Index)란? 🍎
방대한 문서에서 자연어 질의로 전문검색을 위해 키워드를 통해 문서를 빠르게 찾아내기 위해 고안된 방식입니다.
데이터를 Token(Term) 단위로 쪼개어서 정렬 한 후, 해당 토큰이 들어 있는 문서의 식별자를 리스트 형태로 보관하는 것을 말합니다.
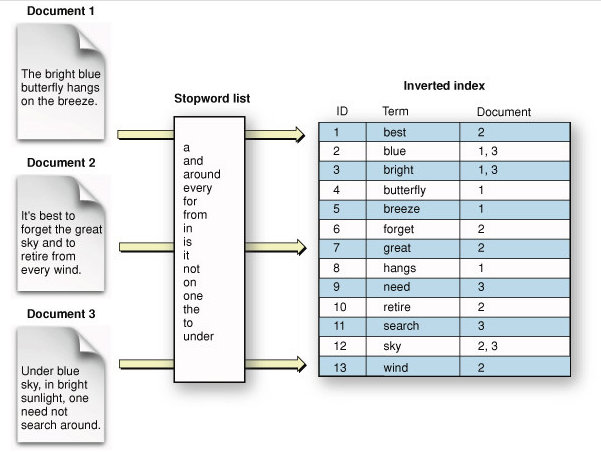
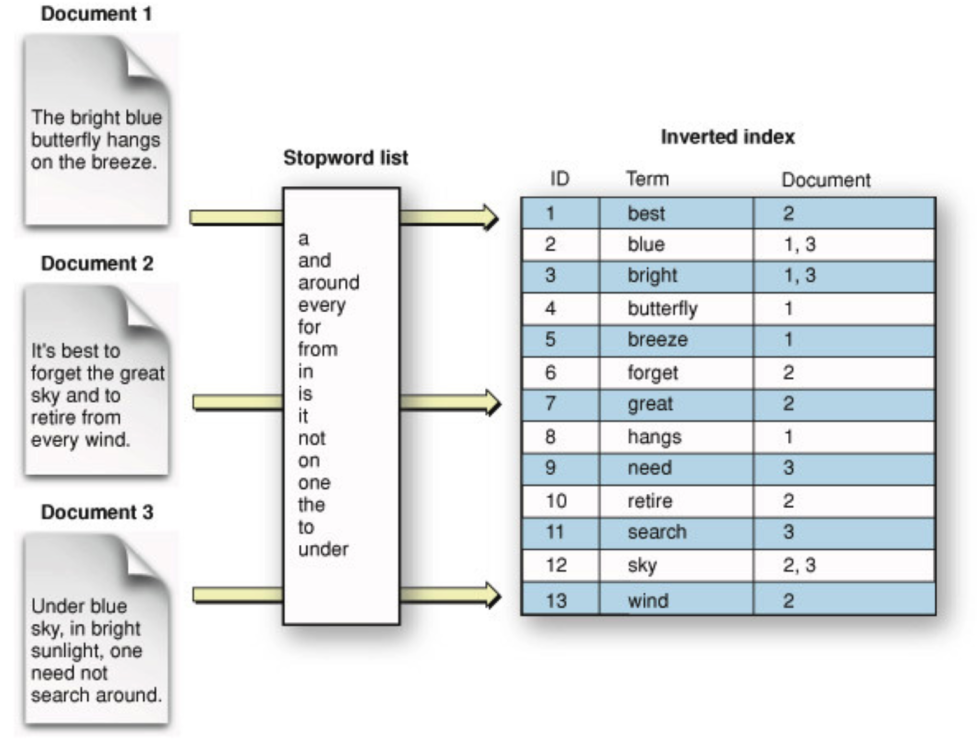
빅데이터 정보검색 시스템에 핵심원리라고 할 수 있습니다.
정보검색(IR : Information Retrieval) 개요
데이터의 집합으로부터 사용자가 요구하는 정보를 탐색하고, 이를 찾아내는 행위
대량의 정보모음으로부터 사용자의 정보요구(need)에 적합한 (relevant) 자료를 찾는 과정(Retrieval)
대량의 자료 집합으로부터 요구사항에 만족하는 (satisfying) 비정형데이터 (주로 자연어 텍스트 문서)를 찾는 것.
정보검색 라이브러리로는 대표적으로 Java기반의 오픈소스 아파치 루씬(Apache Lucene)이 있습니다.
그리고 대표적인 오픈소스 검색엔진인 엘라스틱서치(Elasticsearch) 또한 아파치 루씬기반으로 만들어져 있습니다.
IR(Information Retrieval)의 기본 원리
문서집합 -> [ Indexer(색인) -> Inverted index -> Retriever(검색) ] <-> 질의, 응답 문서
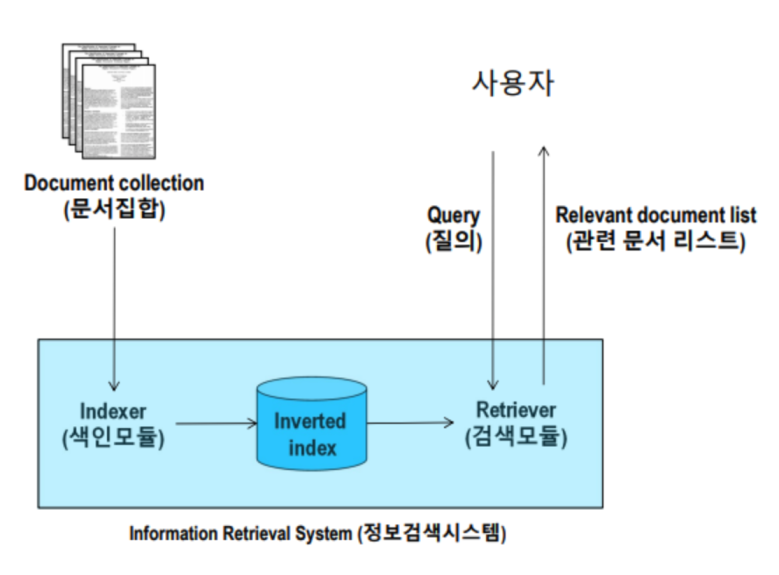
1. 검색에진에 입력되는 데이터를 특정 토크나이저로 분절시켜 역 인덱스를 구성
2. 검색한 질의를 토크나이저로 분절하여, 각 토큰에 대해서 검색을 수행
3. 해당 토큰을 가지고 있는 문서들의 식별자를 역 인덱스에 접근하여 빠르게 찾아냄
색인모듈

1. 텍스트 추출
- 다양한 형식을 가진 문서에서 순수한 텍스트를 추출해냅니다.
2. 토큰 (Token ) 추출
- text를 검색하기 좋게 토큰화 시킵니다.
- 토큰화되어 추출된 키워드는 Term 이라고 부릅니다.
3. 불용어(Stop-word) 제거
- 의미를 가지지않아 필요없는 관용어, 불용어를 제거합니다.
- 불용어란 관사(a, the)처럼 의미를 가지지않는 용어를 말합니다.
4. 정규화 - 의미를 가진 용어를 기본형으로 바꾸고, 어간을 생성합니다.
영어에서는 Stemming(스태밍)이라고 해서 단어에서 항상 고정되는 어간을 추출합니다.

5. 역색인(Inverted Index)
- 문서에서 단어를 찾는 것이 아니라 색인을 통해 단어에서 특정 문서를 찾아내는 방법을 말합니다.
- 토큰화되어 추출된 키워드(Term)이 어떤 문서(Document)에 있는지 검색어 사전을 구성하는 것입니다.
검색모델
1) Corpus(말뭉치): 자료를 검색할 Corpus가 존재해야 한다
2) Topic(주제): 그 Corpus에서 자료를 검색하기 위한 Topic이 존재해야 한다.
3) Relevance(관련성) : 어떠한 문서가 Topic을 포함하고 있으면 Relevance 하다고 한다.
RDMS 검색 🚩 정보검색(IR) 🚩 지식그래프 QA
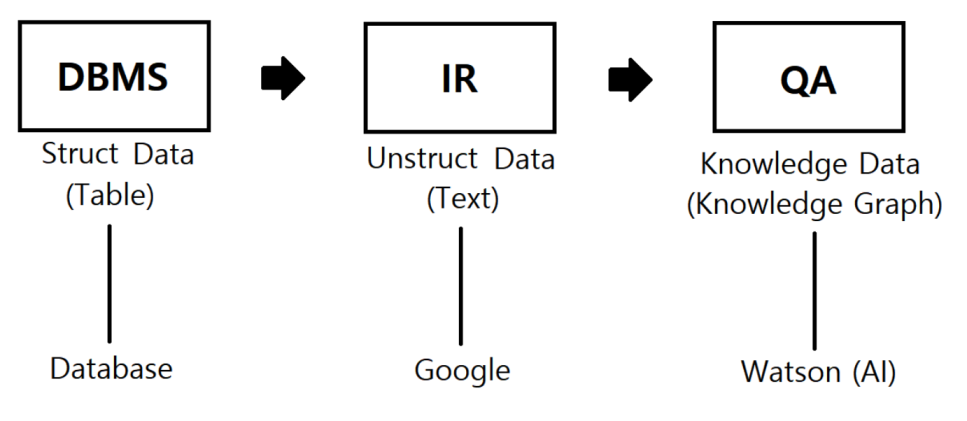
모두 질의(Query) 를 통해서 원하는 데이터를 찾는다. 하지만 DBMS 는 SQL 을 통한 질의를 하고, 정보검색(IR)에서는 자연어 질의를 한다는 차이가 있다.
DBMS 검색은 데이터베이스(정형데이터, 테이블)에서 SQL 질의(Query) 를 이용하여 원하는 정보를 찾는 것. ex) Oracle, Postgresql, Mysql
정보검색(IR) 은 주로 역색인 구조로 색인된 정보검색시스템에 자연어 질의(Query)를 통해 비정형/반정형 데이터에서 정보요구에 적합한 문서를 찾아내는 것 , ex) 엘라스틱서치, 솔라
QA (질의응답 시스템)는 사용자의 자연어 질의(Query)를 해석해서 지식베이스(지식 데이터 또는 지식그래프)에서 원하는 대답을 찾는것. 대개 챗봇에서 인간의 질문에 대답하는 백엔드 처리를 하는 시스템으로 많이 활용
지식그래프(Knowledge Graph)란?
지식그래프를 이해하기 위해서는 먼저 그래프(Graph) 자료구조에 대해서 자세히 알아두면 좋습니다.
그래프(Graph) : 노드(N, node)와 그 노드를 연결하는 간선(E, edge)을 하나로 모아 놓은 자료 구조
지식 그래프(Knowlege Graph)는 개체, 사건 또는 개념과 같은 실체에 대한 상호 연결된 설명 모음을 뜻합니다.
GNN, GCN 등 그래프를 활용한 뉴럴 네트워크의 발전과 함께 지식그래프(Knowledge graph)를 이용하는 분야가 확장되고 있습니다
지식그래프에서는 노드는 entity, 엣지는 entity 간의 relation으로 표현됩니다. 지식그래프는 heterogeneous network라고도 불립니다.
일반적인 그래프와는 달리 entity(노드)와 relation(엣지)에 여러 가지 type이 정의되기 때문입니다.
지식그래프를 이용하면 Intro에서 언급했던 CF-based, Content-based 추천시스템의 단점을 보완하여 추천시스템을 개발할 수 있습니다.
지식그래프를 통해서는 고도의 검색 뿐만 아니라 의미추론, 추천서비스, 기계독해, QA 태스크 등 다양하게 활용 할 수 있습니다.
활용사례
소매: 지식 그래프는 업셀(up-sell) 및 크로스셀(cross-sell) 전략에 활용되며, 개인의 구매 행동과 인구통계학적 그룹 전반에서 인기 있는 구매 경향을 기반으로 제품을 추천합니다.
엔터테인먼트: 지식 그래프는 Netflix, SEO 또는 소셜 미디어와 같은 콘텐츠 플랫폼을 위한 인공 지능(AI) 기반 추천 엔진에도 활용됩니다. 클릭 및 기타 온라인 참여 행동을 기반으로 이러한 제공자는 사용자가 읽거나 시청할 새 콘텐츠를 추천합니다.
금융: 이 기술은 금융 업계 내 고객 유형 파악(KYC) 및 자금세탁방지 이니셔티브에도 사용되었습니다. 즉, 금융 범죄 예방 및 조사를 지원하여 은행 기관이 고객 전체의 자금 흐름을 이해하고 규정을 준수하지 않는 고객을 식별할 수 있도록 합니다.
의료: 지식 그래프는 의료 연구 내에서 관계를 구성하고 분류함으로써 의료 산업에도 도움이 됩니다. 이 정보는 개인의 필요에 따라 진단을 검증하고 치료 계획을 식별함으로써 의료진을 지원합니다.
지식그래프에 대한 내용은 여기에 아주 잘 정리가 되어있는 것 같습니다.
본 글은 다음을 참고하여 작성되었습니다.

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>