@senspond
>
서울시 부동산 실거래가 정보_2023 기반으로 한 파이썬 데이터 시각화 연습
서울시 부동산 실거래가 정보_2023 기반으로 한 파이썬 데이터 시각화 연습해본 글입니다.
안녕하세요. 파이썬 데이터 시각화 실 데이터를 기반으로 실습을 해보았습니다. 그 내용을 정리해봅니다.
사전준비
서울시 부동산 실거래가 정보
https://data.seoul.go.kr/dataList/OA-21275/S/1/datasetView.do
데이터는 접수연도 2023 인 것으로 필터링하여 뽑았습니다.
필수 패키지 설치
pip install numpy
pip install pandas
pip install matplotlib
pip install seaborn맥에서 matplotlib 한글폰트 적용하는 방법
import matplotlib.pyplot as plt
plt.rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] =False애플 시스템 폰트인 ApplieGothic 을 사용하면 한글이 안깨지고 나옵니다. 윈도우라면 나눔고딕 폰트를 설치해서 넣어줍니다.
데이터 로드
데이터 프레임으로 로드
import pandas as pd
import seaborn as sns
house_df = pd.read_csv('../files/서울시 부동산 실거래가 정보_2023.csv',encoding='ms949')
house_df
데이터 프레임 정보 확인
# 데이터 프레임 정보
house_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69536 entries, 0 to 69535
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 접수연도 69536 non-null int64
1 자치구코드 69536 non-null int64
2 자치구명 69536 non-null object
3 법정동코드 69536 non-null int64
4 법정동명 69536 non-null object
5 지번구분 66818 non-null float64
6 지번구분명 66818 non-null object
7 본번 66818 non-null float64
8 부번 66818 non-null float64
9 건물명 66822 non-null object
10 계약일 69536 non-null int64
11 물건금액(만원) 69536 non-null int64
12 건물면적(㎡) 69536 non-null float64
13 토지면적(㎡) 69536 non-null float64
14 층 66831 non-null float64
15 권리구분 593 non-null object
16 취소일 3260 non-null float64
17 건축년도 69155 non-null float64
18 건물용도 69536 non-null object
19 신고구분 69516 non-null object
20 신고한 개업공인중개사 시군구명 57302 non-null object
dtypes: float64(8), int64(5), object(8)
memory usage: 11.1+ MB숫자로 표현할 수 있는 수치형 데이터가 무엇무엇이고 숫자로 표현할 수 없는 범주형 데이터가 무엇인지 파악해봅니다.
그리고 이 데이터를 가지고 무엇을 분석해 볼 수 있을지 파악해봅니다.
결측치 확인 / 불필요한 컬럼 제거
house_df.isnull().sum()각 컬럼마다 값이 비어있는 로우의 갯수가 몇개가 되는지 확인해봅니다.
접수연도 0
자치구코드 0
자치구명 0
법정동코드 0
법정동명 0
지번구분 2718
지번구분명 2718
본번 2718
부번 2718
건물명 2714
계약일 0
물건금액(만원) 0
건물면적(㎡) 0
토지면적(㎡) 0
층 2705
권리구분 68943
취소일 66276
건축년도 381
건물용도 0
신고구분 20
신고한 개업공인중개사 시군구명 12234
dtype: int64house_df.isnull().mean()각 컬럼마다 값이 비어있는 로우의 빈도가 어떻게 되는지 평균을 내어 확인해봅니다. 1이면 100% 비어있다는 의미가 되니 1에 가까울 수록 비어있는 빈도가 높다는 의미입니다.
접수연도 0.000000
자치구코드 0.000000
자치구명 0.000000
법정동코드 0.000000
법정동명 0.000000
지번구분 0.039088
지번구분명 0.039088
본번 0.039088
부번 0.039088
건물명 0.039030
계약일 0.000000
물건금액(만원) 0.000000
건물면적(㎡) 0.000000
토지면적(㎡) 0.000000
층 0.038901
권리구분 0.991472
취소일 0.953118
건축년도 0.005479
건물용도 0.000000
신고구분 0.000288
신고한 개업공인중개사 시군구명 0.175938
dtype: float64권리구분과 취소일은 0.9 이상으로 의미가 없는 컬럼으로 간주할 수 있습니다.
그외 분석하려는 목적에 불필요한 컬럼을 날려줍니다.
# 불필요한 컬럼 삭제
df = house_df.drop(columns=['권리구분','취소일','지번구분','지번구분명','본번','부번','신고구분','신고한 개업공인중개사 시군구명'])원본 house_df 를 수정해버리면 원본데이터가 필요할때 다시 불러와야 하니 새로운 데이터프레임으로 받도록 합니다.
데이터 시각화
건물용도별 건수
간단하게 건물용도별 건수를 시각화 해봅니다.
막대그래프
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(df, x="건물용도")
plt.show()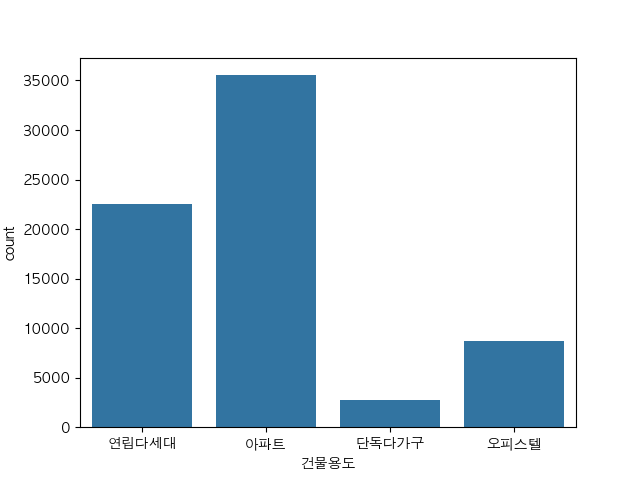
아파트 거래건수가 가장 많다는 것을 알 수가 있습니다.
파이그래프
import numpy as np
tdf = df['건물용도'].value_counts()
explodes = np.full((len(tdf)), 0.04).tolist()
tdf.plot(kind = "pie", autopct = "%1.1f%%", startangle = 100, explode=explodes)
plt.ylabel('')
plt.show()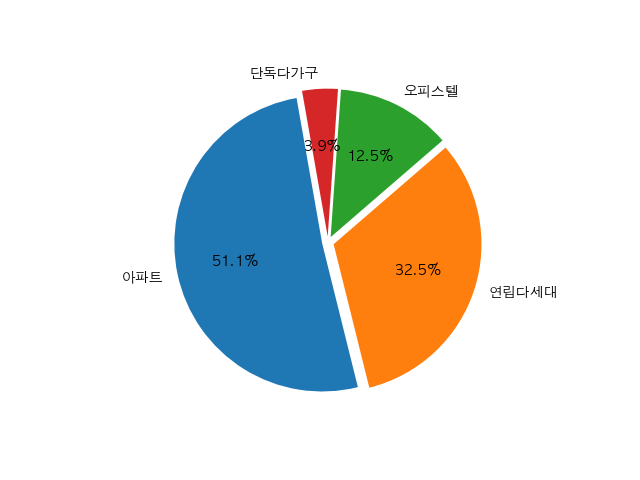 건물용도 아파트인 데이터로 필터링
건물용도 아파트인 데이터로 필터링
여기서는 건물용도가 아파트인 데이터만 가지고 분석을 해보기로 했습니다.
# 건물용도가 아파트인 데이터만 추출
apt_df = df[df['건물용도'] == '아파트'].reset_index(drop=True)
apt_df.head(2).T # 보기좋게 모양확인하기 위해 2개만 뒤집어서 0 | 1 | |
|---|---|---|
접수연도 | 2023 | 2023 |
자치구코드 | 11440 | 11545 |
자치구명 | 마포구 | 금천구 |
법정동코드 | 12600 | 10200 |
법정동명 | 중동 | 독산동 |
건물명 | 현대 | 한신아파트 |
계약일 | 20231230 | 20231229 |
물건금액(만원) | 58000 | 59800 |
건물면적(㎡) | 59.54 | 89.46 |
토지면적(㎡) | 0.0 | 0.0 |
층 | 1.0 | 5.0 |
건축년도 | 2000.0 | 1991.0 |
건물용도 | 아파트 | 아파트 |
자치구별로 아파트 거래량/평균 거래가 구하기
다중컬럼 그룹바이
gdf = apt_df.groupby(['자치구명']).agg({'자치구명' : "count", '물건금액(만원)' : "mean"})
gdf = gdf.rename(columns={"자치구명" : "거래량", "물건금액(만원)" : '평균거래가'})
gdf.head()거래량 | 평균거래가 | |
|---|---|---|
자치구명 | ||
강남구 | 2402 | 217555.920899 |
강동구 | 2269 | 103479.213751 |
강북구 | 849 | 51173.938751 |
강서구 | 1786 | 74794.540873 |
관악구 | 1022 | 67259.685910 |
자치구별 아파트 거래량 시각화
자치구별 아파트 거래량을 막대그래프로 시각화 해보겠습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
# 거래량 순으로 내림차순해서 막대그래프로
sns.barplot(gdf['거래량'].sort_values(ascending=False))
plt.show()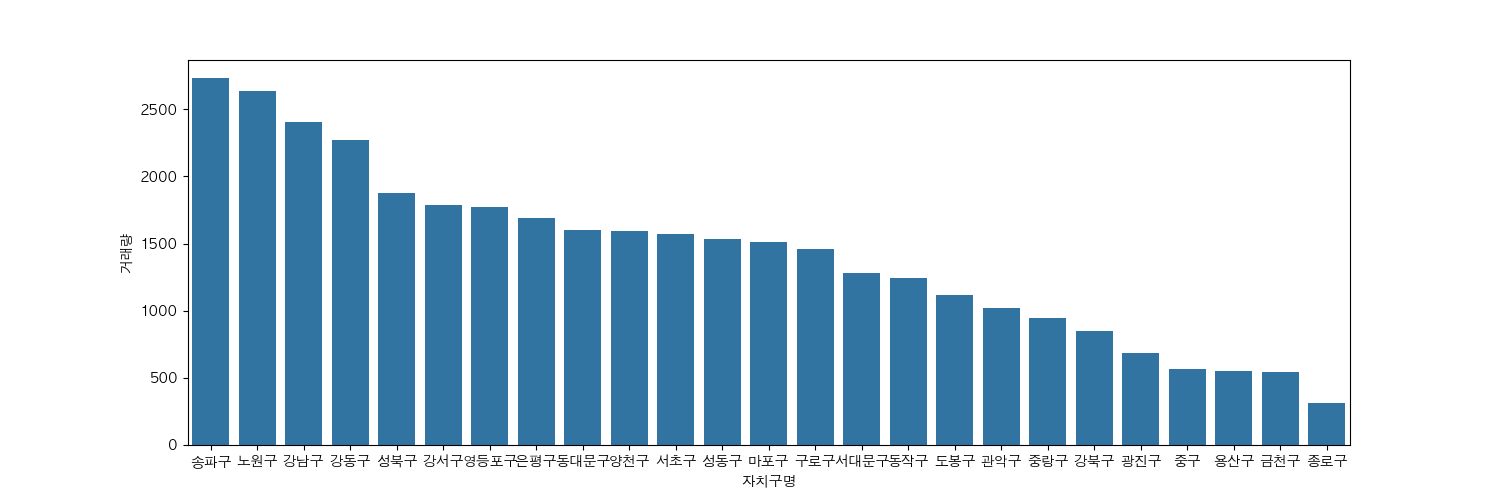
아파트 거래물건 개수는 송파구, 노원구, 강남구, 강동구, 성복구 순으로 많다는 것을 시각적으로 확인할 수 있네요.
2023년 아파트 거래량이 가장 많은 지역 : 송파구
2023년 아파트 거래량이 가장 적은 지역 : 종로구
자치구별 아파트 평균거래가 시각화
이번에는 자치구별 아파트 평균거래가를 막대그래프로 시각화 해보겠습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
# 자치구명에 대한 카운트를 내림차순해서 막대그래프로
sns.barplot(gdf['평균거래가'].sort_values(ascending=False))
plt.ylabel('평균거래가(만원)')
plt.show()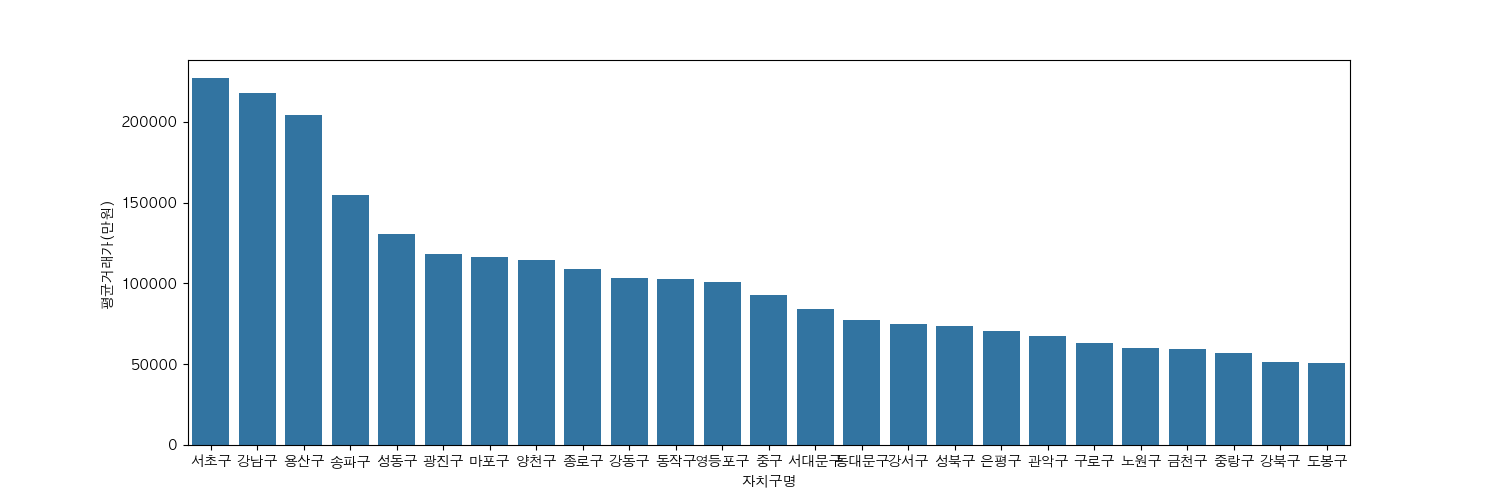
아파트는 서초구,강남구,용산구 순으로 평균거래가가 높다는 것을 알 수 있네요. 비싼동네입니다.
자치구별 아파트 거래량 & 평균거래가 시각화
이번에는 자치구별 아파트 거래건수와 평균거래가를 한 차트안에 같이 드려보도록 하겠습니다.
서로 다른 범위를 가진 데이터 한차트안에 그리게 되면 ?
import numpy as np
idx = np.arange(0, len(gdf)) #행의 갯수를 리스트로
w = 0.2
plt.figure(figsize = (17, 4))
plt.bar(idx - w, gdf['거래량'], width=w,label='거래량')
plt.bar(idx + w, gdf['평균거래가'], width=w,label='평균거래가(만원)')
# x축 위치조정/텍스트 정보와 매칭
plt.xticks(np.arange(0, len(gdf), 1), list(gdf.index))
plt.xlabel('자치구명', size = 12)
plt.ylabel('수치', size = 12)
plt.legend()
plt.savefig('./막대3.png')
plt.show()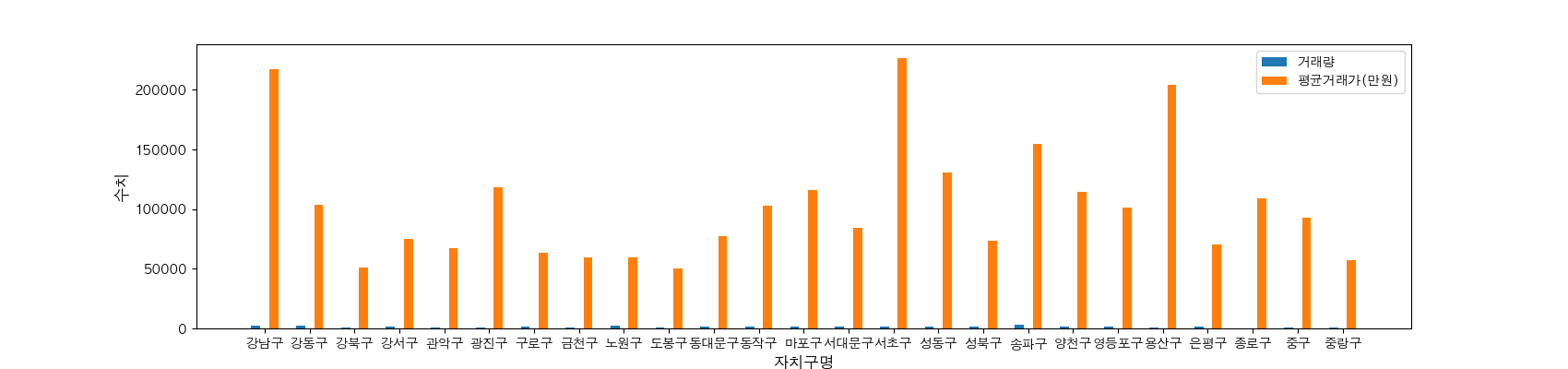
거래건수랑 평균거래가 수치가 너무 차이가 크기때문에 한 차트에 넣으면 이렇게 나옵니다. 서로 다른 두 데이터를 같이 넣고 비교하기 위한 스케일링 작업을 합니다. 여기서 제가 사용해 볼 방식은 최소값 - 최대값 정규화(min-max normalization) 입니다. 그냥 단순하게 서로 다른 범위를 가진 데이터를 비교를 하기 위해서 모두 0과 1사이로 들어오도록 만드는 것입니다.
min-max normalization 적용하기
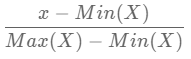
MinMaxScaler 을 간단하게 적용하기 위해 머신러닝 패키지인 싸이킷런을 설치합니다.
pip install scikit-learnfrom sklearn.preprocessing import MinMaxScaler
ms = MinMaxScaler()
output = ms.fit_transform(gdf)
odf = pd.DataFrame(output, columns=['거래건_T', '거래가_T'], index=list(gdf.index.values))
odf.head()거래건_T | 거래가_T | |
|---|---|---|
강남구 | 0.864519 | 0.947218 |
강동구 | 0.809583 | 0.300091 |
강북구 | 0.223048 | 0.003377 |
강서구 | 0.610078 | 0.137370 |
관악구 | 0.294506 | 0.094627 |
normalization 후 비교차트
다시 차트를 다시 그려봅니다.
import numpy as np
idx = np.arange(0, len(gdf)) #행의 갯수를 리스트로
w = 0.2
plt.figure(figsize = (17, 4))
plt.bar(idx - w, odf['거래건_T'], width=w,label='거래량')
plt.bar(idx + w, odf['거래가_T'], width=w,label='평균거래가')
plt.xticks(np.arange(0, len(gdf), 1), list(gdf.index))
plt.xlabel('자치구명', size = 12)
plt.ylabel('수치', size = 12)
plt.legend()
plt.show()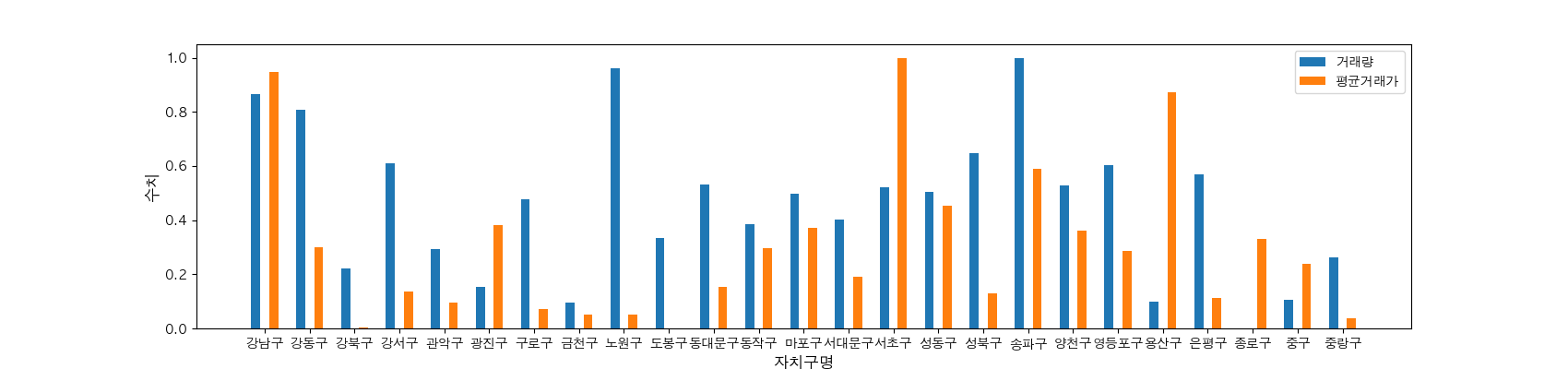
이렇게 그려보니까 노원구는 거래량에 비해 상대적으로 평균거래가가 많이 낮게 비교됬고
용산구 아파트는 상대적으로 거래량에 비해서 평균거래가가 굉장히 높은 특이점을 발견하게 됬습니다.
gdf.loc[['노원구','용산구']]거래량 | 평균거래가 | |
|---|---|---|
자치구명 | ||
노원구 | 2633 | 59738.235853 (만원) |
용산구 | 550 | 204288.252727 (만원) |
2023년 서울시 부동산 관련 기사들을 찾아봤더니 이런내용이 있네요.
" 유독 용산구의 거래량이 주춤한 이유는 다주택에 대한 취득세 중과 부담이 꼽힌다. 용산구는 실수요도 있지만 다주택자의 가수요도 적지 않은 곳으로 꼽힌다. 용산의 미래 가치를 감안한 수요가 적지 않은데 아직은 취득세 부담이 발목을 잡고 있다고 분석한다."
출처 : https://news.mt.co.kr/mtview.php?no=2023051614354839485
월별 계약건수 시각화
계약일이 20231106 와 같이 있어서 년과 월을 구분해 컬럼을 추가로 달아줬습니다.
apt_df['계약년'] = apt_df['계약일'].apply(lambda x : str(x)[0:4])
apt_df['계약월'] = apt_df['계약일'].apply(lambda x : str(x)[4:6])
mdf = apt_df[apt_df['계약년'] == '2023'].groupby(['계약월'])['계약일'].count()서울시 부동산 실거래가 정보 신고년도는 2023 으로 필터링해서 뽑았는데 계약은 2022년에 한것도 있었습니다. 그래서 계약년이 2023 인 것만으로 집계를 해봤습니다.
plt.figure(figsize=(12, 4))
plt.title('2023년 서울시 아파트 월별 계약건수')
plt.ylabel('계약건수')
sns.lineplot(mdf)
plt.show()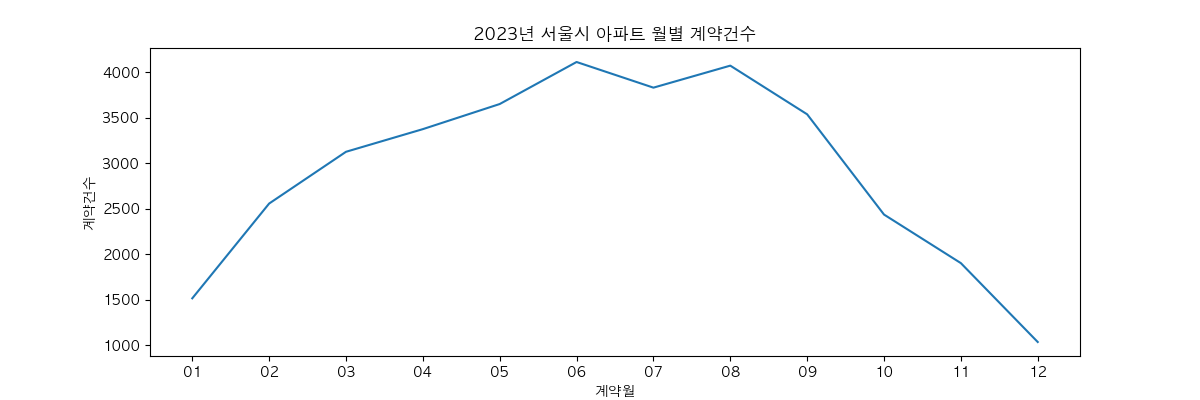
5~7월에 계약이 많이 있었고 월초와 연말에는 적었네요.
건물면적과 거래가의 상관관계
adf = apt_df[['층', '물건금액(만원)','건물면적(㎡)']]
sns.scatterplot(adf, x="건물면적(㎡)", y="물건금액(만원)")
plt.show()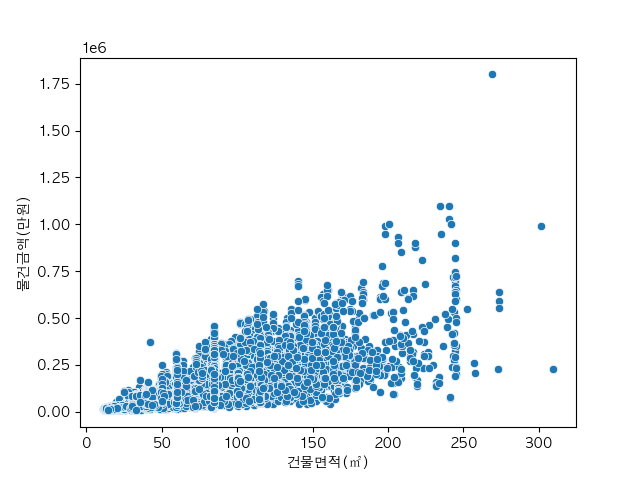
아파트 건물면적과 물건가격이 어떤 상관관계가 있을지 확인해보기 위해 산점도 차트를 그려봅니다. 집의 평수가 넓을 수록 가격이 올라가는 양의 상관관계가 있다는 것을 확인할 수 있네요.
건물층수와 거래가의 상관관계
sns.scatterplot(adf, x="층", y="물건금액(만원)")
plt.show()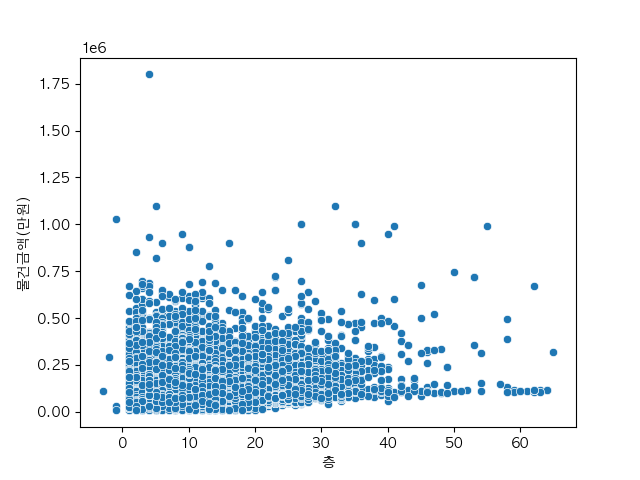 이번에는 아파트 층수와 가격의 산점도 입니다. 건물 면적에 비해서는 양의 상관관계가 약하게 나왔네요. 고층선호/저층선호 개인선호도 차이도 있을 것 같습니다.
이번에는 아파트 층수와 가격의 산점도 입니다. 건물 면적에 비해서는 양의 상관관계가 약하게 나왔네요. 고층선호/저층선호 개인선호도 차이도 있을 것 같습니다.
본글은 서울시 부동산 실거래가 정보_2023 기반으로 한 파이썬 데이터 시각화 연습해본 글입니다. 데이터의 누락 건수가 다소 있을 수 있다고 하니 보다 정확하게는 국토교통부 실거래가 데이터를 기준으로 해야할 것 같습니다.

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>