@senspond
>
최근접이웃 알고리즘(K-Neighbors, KNN)을 통한 아이리스(iris) 품종분류
사이킷런(sklearn)의 최근접이웃 알고리즘(K-Neighbors, KNN)분류모델(KNeighborsClassifier)을 통한 아이리스(iris) 데이터의 품종분류 해보는 글입니다.

데이터셋 로드
seaborn 에 내장되어 있는 iris 붗꽃 데이터를 가져옵니다.
import matplotlib.pyplot as plt
import seaborn as sns
iris = sns.load_dataset("iris")
iri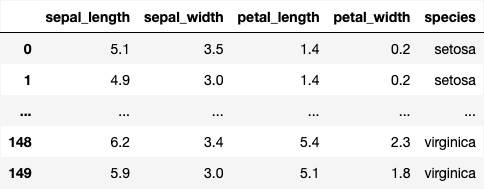
시각화
sns.pairplot(data=iris, hue="species")
plt.show()pairplot은 가운데 대각은 distplot을 그려주고, 나머지는 scatter plot을 그려줍니다.
매개변수들 간의 상관관계가 어떻게 되는지 한눈에 파악해봅니다.
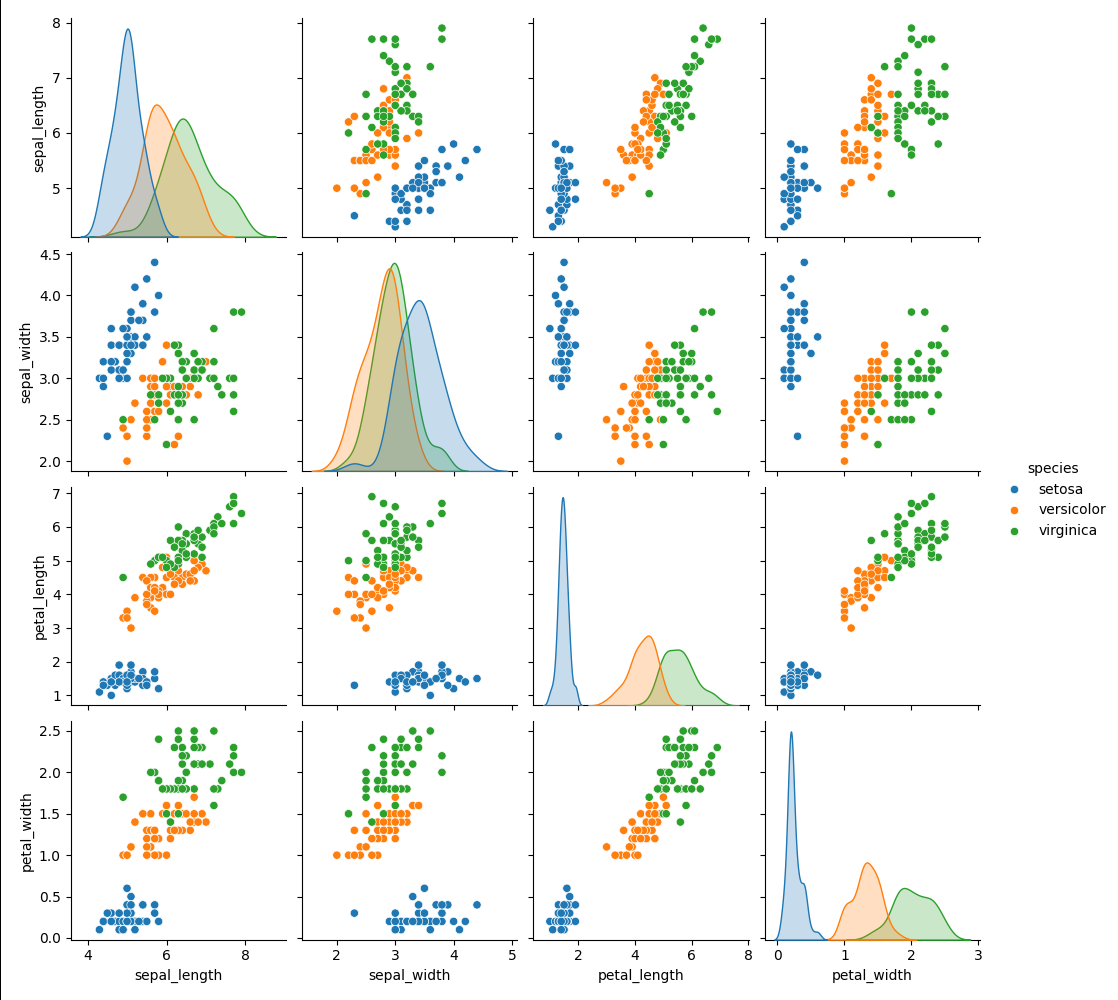
모델을 만들때 어떤 매개변수가 결과값이 큰 영향을 주게 될지.. 시각화를 통해 파악을 해볼 수 있습니다.
그런데 머신러닝에서 실제로 모델을 만들었을때는 전혀 영향을 주지 않을 것 같은 매개변수가 영향을 주는 경우도 많이 있습니다. 그래서 반복적으로 해봐야합니다.
품종 분류문제
주어진 데이터를 가지고 지도학습을 하여 새로운 데이터가 주어졌을때 분류모델로 품종을 분류하는 문제입니다.
여기서는 최근접이웃 알고리즘(K-Neighbors, KNN) 분류 모델을 통해서 학습을 하고 분류를 해보도록 하겠습니다. 간편하게 sklearn 모듈을 사용합니다.
최근접이웃 알고리즘(K-Neighbors, KNN)
거리기반 모델로 고전적이고 기본적인 머신러닝 알고리즘 중 하나입니다. 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘으로 거리를 측정할때 '유클리디안 거리' 계산법을 사용합니다.
사이킷런에서 KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()주요 Parameters:
- n_neighbors: kNN algorithm에 이용할 neighbor의 개수.
- algorithm: nearest neighbor을 계산할 때 사용할 algorithm의 종류. 'ball_tree', 'kd_tree', 'brute', 'auto'를 사용할 수 있으며 'auto'는 자동으로 가장 적합한 algorithm을 찾아준다.
- leaf_size: BallTree나 KDTree 사용 시에 설정할 leaf size. Algorithm의 속도나 memory 크기, 모델의 성능에 영향을 미친다.
- metric: distance metric의 종류. 'euclidean', 'manhattan', 'chebyshev', 'minkowsk' 등을 사용할 수 있으며 전체 metric에 대한 설명은 여기에서 확인할 수 있다.
모델 학습하고 평가하기
우선 petal_length, petal_width 두개의 매개변수로 모델을 만들어봅니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = \
train_test_split(iris[["petal_length", "petal_width"]],iris['species'], test_size=0.3, random_state=40)
# 데이터 스케일링
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
# 최근접이웃(KNN)알고리즘으로 분류모델 학습
kn = KNeighborsClassifier(n_neighbors=5)
kn.fit(X_train_scaled, y_train)
# 평가
kn.score(X_test_scaled, y_test)1.0
random_state 는 매번 실행할때마다 분할된 데이터가 바뀌기 때문에 랜덤 시드값을 줘서 고정시키는 옵션입니다.
그런데 random_state 값에 따라서 모델의 평가지수가 상당히 많이 상당히 달라짐을 알 수가 있었습니다.
데이터 스케일링을 해주는 이유는 매개변수들 간의 데이터의 범위를 일정하게 맞춰서 KNN 알고리즘으로 이웃이 잘못 선택되는 현상을 방지하기 위한것입니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
score_list = []
# 1000번 돌려서
for i in range(1000):
# 훈련/테스트 데이터 분할
X_train, X_test, y_train, y_test = \
train_test_split(iris[["sepal_length", "petal_length"]],iris['species'], test_size=0.3)
# 데이터 스케일링
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
# 최근접이웃(KNN)알고리즘으로 분류모델 학습
kn = KNeighborsClassifier(n_neighbors=5)
kn.fit(X_train_scaled, y_train)
# 평가
score = kn.score(X_test_scaled, y_test)
score_list.append(score)
# 평가 평균
sn = np.array(score_list)
print(f"최소 : {sn.min()}")
print(f"평균 : {sn.mean()}")
print(f"최대 : {sn.max()}")최소 : 0.8444444444444444
평균 : 0.963088888888889
최대 : 1.0
1000번을 랜덤하게 훈련/테스트 데이터를 뽑아서 학습시키고 평가해보니 차이가 났습니다. 이로써 훈련데이터랑 테스트용 데이터를 어느 한쪽에 편중되게 분할하게 되면 모델성능에 영향을 줄 수가 있다는 것을 확인 할 수가 있습니다.
그러니까 train_test_split 메소드의 매개변수 stratify 에 클래스 분포 비율(품종별)로 균일하게 분할 되도록 stratify=iris['species'] 을 추가합니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
score_list = []
# 1000번 돌려서
for i in range(1000):
# 훈련/테스트 데이터 분할
X_train, X_test, y_train, y_test = \
train_test_split(iris[["petal_length", "petal_width"]],iris['species'], test_size=0.3, stratify=iris['species'])
# 데이터 스케일링
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
# 최근접이웃(KNN)알고리즘으로 분류모델 학습
kn = KNeighborsClassifier(n_neighbors=5)
kn.fit(X_train_scaled, y_train)
# 평가
score = kn.score(X_test_scaled, y_test)
score_list.append(score)
# 평가 평균
sn = np.array(score_list)
print(f"최소 : {sn.min()}")
print(f"평균 : {sn.mean()}")
print(f"최대 : {sn.max()}")최소 : 0.8888888888888888
평균 : 0.9662222222222223
최대 : 1.0
모든 매개 변수(품종제외)를 다 넣고 학습시켜서 평가해봅니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
score_list = []
# 1000번 돌려서
for i in range(1000):
# 훈련/테스트 데이터 분할
X_train, X_test, y_train, y_test = \
train_test_split(iris.iloc[:,:-1],iris['species'], test_size=0.3, stratify=iris['species'])
# 데이터 스케일링
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
# 최근접이웃(KNN)알고리즘으로 분류모델 학습
kn = KNeighborsClassifier(n_neighbors=5)
kn.fit(X_train_scaled, y_train)
# 평가
score = kn.score(X_test_scaled, y_test)
score_list.append(score)
# 평가 평균
sn = np.array(score_list)
print(f"최소 : {sn.min()}")
print(f"평균 : {sn.mean()}")
print(f"최대 : {sn.max()}")최소 : 0.8444444444444444
평균 : 0.9508000000000001
최대 : 1.0
petal_length, petal_width 두개의 매개 변수로 만든 모델이 모든 매개변수를 학습시킨 모델보다 평균적으로 미세하게 좀더 낳은 성능을 보일 수 있다는 결과였지만, 거의 차이는 없었습니다.
그런데 iris 데이터 셋의 레코드가 150개 밖에 되지 않고 그중의 70% 데이터로 학습(test_size 0.3) 하였기 때문에 좀더 많은 데이터로 학습 시켰을 때는 어떤 차이가 있을지는 알 수가 없습니다. 주어진 데이터내에서는 그러했다는 것입니다.
새로운 데이터 분류
여기서는 두개 매개변수(petal_length, petal_width)만 가지고 학습시킨 모델로 분류를 해보겠습니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = \
train_test_split(iris[["petal_length", "petal_width"]],iris['species'], test_size=0.3, random_state=40, stratify=iris['species'])
# 데이터 스케일링
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
# 최근접이웃(KNN)알고리즘으로 분류모델 학습
kn = KNeighborsClassifier(n_neighbors=5)
kn.fit(X_train_scaled, y_train)
# 평가
kn.score(X_test_scaled, y_test)이 모델을 사용해 이번에는 새로운 데이터를 분류를 해보겠습니다.
그런데 데이터 스케일링을 하여 학습을 시켰기에, 마찬가지로 스케일링 된 데이터를 넣고 예측(predict) 해야합니다.
또한 학습을 시켰을때의 자료형태로 맞춰줘야 합니다.
scaled_search_point =ss.transform(pd.DataFrame({
"petal_length" : [4],
"petal_width" : [2]
}))
print(kn.predict(scaled_search_point))['virginica']
petal_length 4 와 petal_width 2는 'virginica' 라고 분류하네요.
KNN으로 선택된 점을 표시하여 시각화
KNN을 통한 분류기능과 최근접 이웃 어떤 점들이 선택되었기에 그렇게 분류 되었는지 보기좋게 시각화를 포함한 클래스를 만들어 봤습니다. 두개의 매개변수만 사용할 것이기에 인자 명칭을 X, Y로 주었습니다.
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
class IrisClassifier():
def __init__(self, X, Y) -> None:
iris = sns.load_dataset("iris")
self.X = X
self.Y = Y
self.source = iris[[X,Y]]
self.target = iris['species']
def lmplot(self):
sns.lmplot(data= iris, x=self.X, y=self.Y, hue="species")
plt.show()
def fit_and_score(self, test_size=0.3, random_state=50, n=5):
"""훈련 데이터와 학습데이터 나눈 후 스케일링하여 지도학습/평가"""
X_train, X_test, self.y_train, self.y_test = \
train_test_split(self.source, self.target, test_size=test_size, random_state=random_state, stratify=iris['species')
self.X_train_scaled = ss.fit_transform(X_train)
self.X_test_scaled = ss.transform(X_test)
# 최근접이웃 알고리즘 (KNN) 모델로 학습
kn = KNeighborsClassifier(n_neighbors=n)
kn.fit(self.X_train_scaled, self.y_train)
self.kn = kn
# 평가
return kn.score(self.X_test_scaled, self.y_test)
def predict_and_draw(self, x, y):
"""x,y 매개변수로 품종 분류(예측) 하고 종합 시각화"""
search_point = pd.DataFrame({
self.X : [x],
self.Y : [y]
})
scaled_search_point = ss.transform(search_point)
print('분류결과 : ' + self.kn.predict(scaled_search_point))
distances, indexes = self.kn.kneighbors(scaled_search_point)
df = pd.DataFrame({
self.X : self.X_train_scaled[:,0],
self.Y : self.X_train_scaled[:,1],
'species' : self.y_train
})
setosa_df = df[df['species'] == 'setosa']
versicolor_df = df[df['species'] == 'versicolor']
virginica_df = df[df['species'] == 'virginica']
plt.scatter(setosa_df[self.X], setosa_df[self.Y], label='setosa')
plt.scatter(versicolor_df[self.X], versicolor_df[self.Y], label='versicolor')
plt.scatter(virginica_df[self.X], virginica_df[self.Y], label='virginica')
plt.scatter(self.X_train_scaled[indexes, 0], self.X_train_scaled[indexes, 1], marker='D', c='y', label ='KN')
plt.scatter(scaled_search_point[:,0], scaled_search_point[:,1], marker='^', c='black', label ='SP')
plt.legend()
plt.xlabel("s_" + self.X)
plt.ylabel("s_" + self.Y)
plt.show()
sepal_length, petal_length
ic = IrisClassifier(X="sepal_length", Y="petal_length")
ic.lmplot()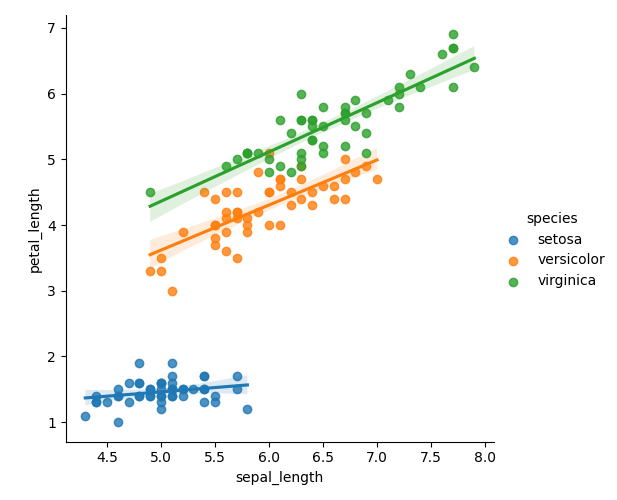
ic.fit_and_score(random_state=40, n=5)0.9555555555555556
여기서 x=6, y=5 일때 어떻게 분류하는지를 한번 봅니다.
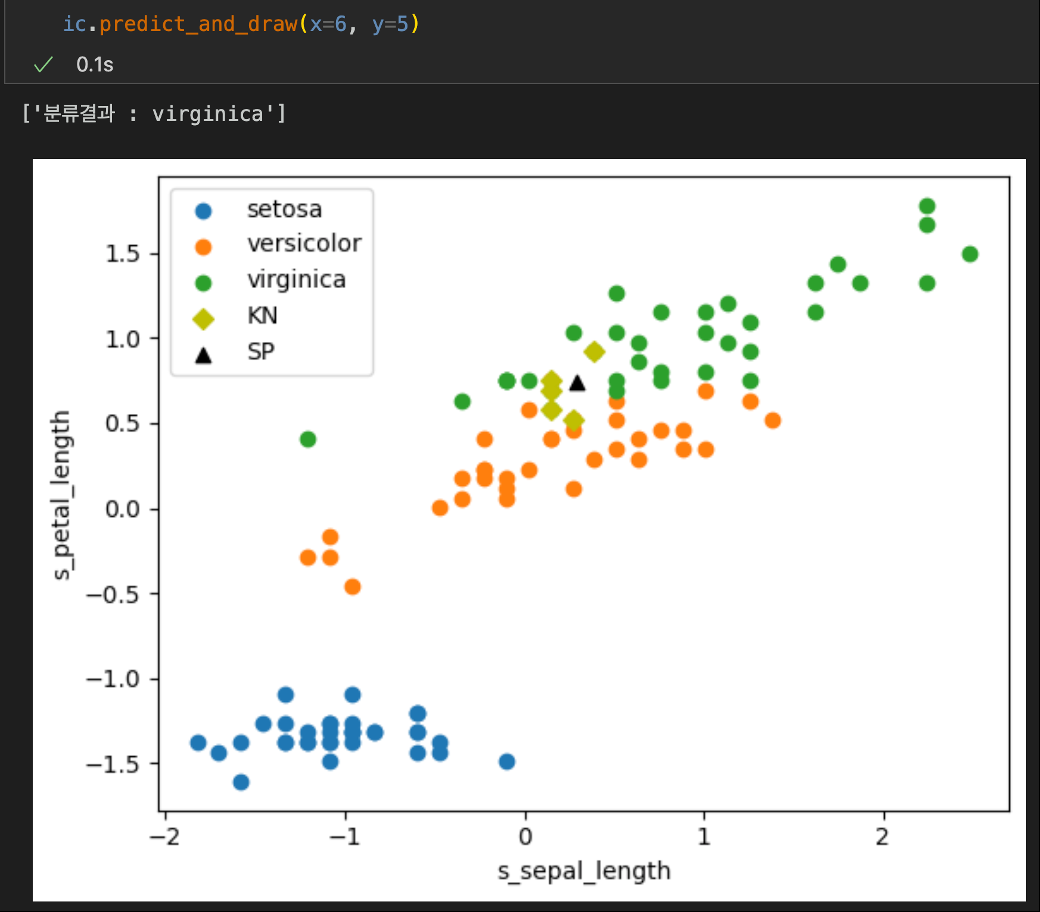
검은색(SP)은 내가 찍은 점이고 노랑색(KN)은 KNN 알고리즘으로 선택한 이웃 점 들입니다.
petal_length, petal_width
ic = IrisClassifier(X="petal_length", Y="petal_width")
ic.lmplot()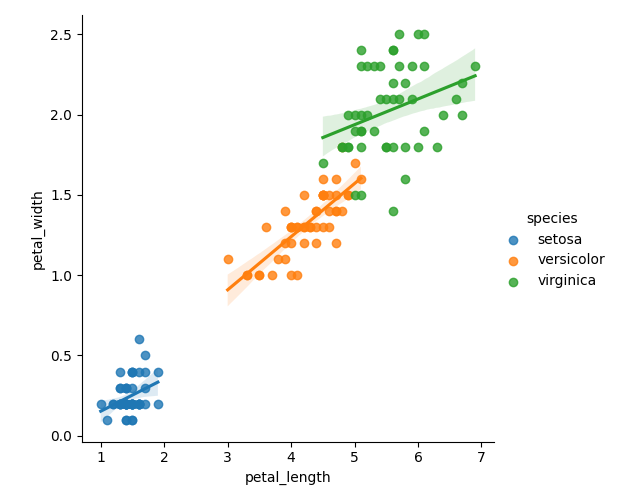
ic.fit_and_score(random_state=40, n=5)1.0
petal_length 가 5이고 petal_width 가 1.5 인 대상을 분류(classification) 를 해봅니다.
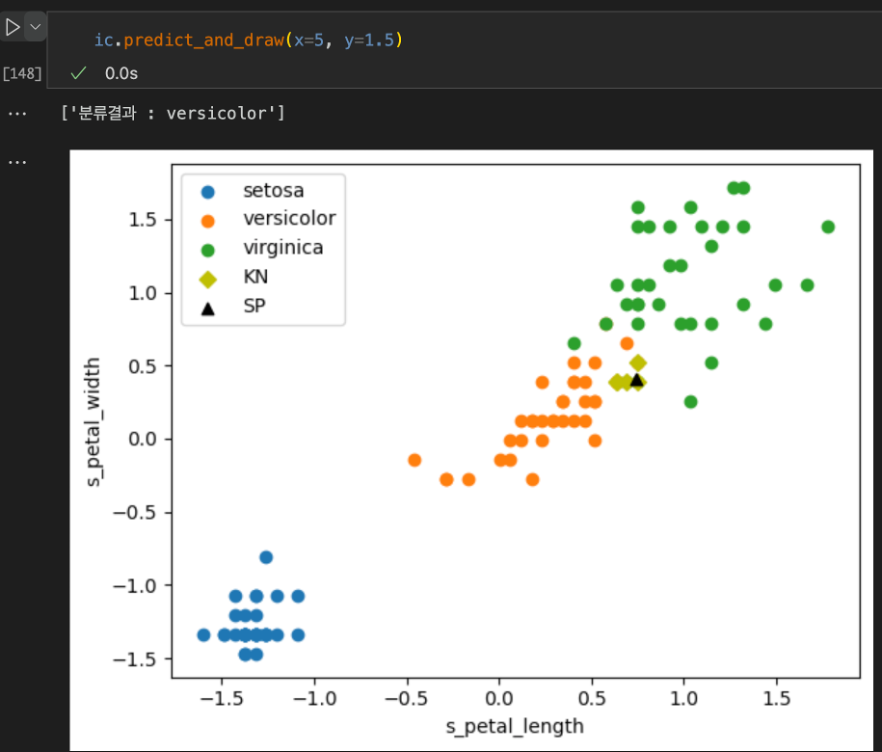

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>