@senspond
>
시그모이드(Sigmoid) 활성화 함수에 대해 알아보고 파이썬으로 구현해보기
시그모이드(Sigmoid) 활성함수에 대해 알아보고 파이썬으로 구현해보는 내용을 정리해봤습니다.
활성화 함수는 인공 신경망에서 입력을 변환하는 함수(activation function)을 의미합니다. 대표적으로 ReLU, 시그모이드 함수, 쌍곡탄젠트 함수 등이 있습니다.
시그모이드 함수란?
시그모이드 함수에 대한 설명은 reference 글을 참고 하였습니다.
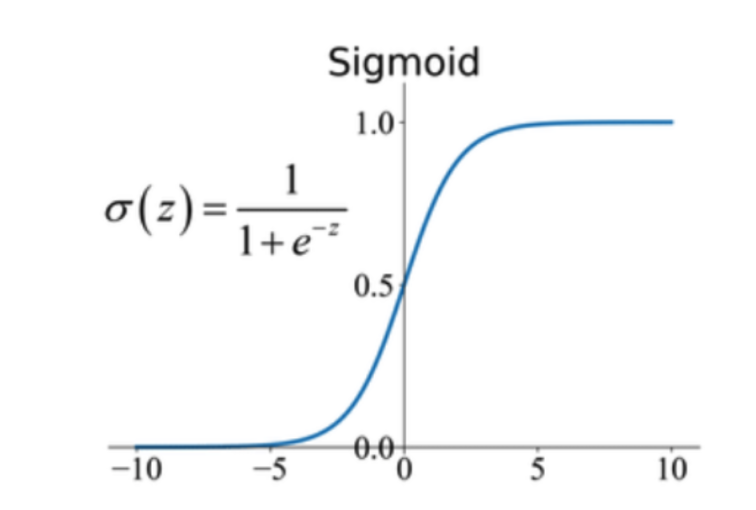
시그모이드(Sigmoid) 함수는 딥러닝에서 널리 사용되는 활성화 함수 중 하나입니다. 이 함수는 0과 1 사이의 값을 출력하며, 입력값을 확률로 변환하는 데에 사용됩니다. 시그모이드 함수는 로지스틱 함수(Logistic function)라고도 불리기도 합니다.
시그모이드 함수의 장단점
시그모이드 함수의 장점
S자 형태: 시그모이드 함수는 입력값이 증가함에 따라 출력값이 S자 형태로 변하는 특징을 가지고 있습니다. 이는 입력값의 변화에 따른 출력값의 부드러운 변화를 의미하며, 딥러닝에서 활성화 함수로 많이 사용되는 이유 중 하나입니다.
비선형 함수: 시그모이드 함수는 비선형 함수(non-linear function)로 분류됩니다. 비선형 함수는 다층 퍼셉트론(Multi-Layer Perceptron) 등의 신경망에서 사용되어야 효과적으로 모델을 학습시킬 수 있습니다. 선형 함수만을 사용하면 신경망의 층을 깊게 쌓는 의미가 없어져서 효과적인 학습이 어려워질 수 있습니다.
확률값 변환: 시그모이드 함수는 입력값을 0부터 1 사이의 확률값으로 변환할 수 있습니다. 따라서 이진 분류(Binary Classification) 문제에서 모델의 출력값으로 사용됩니다.
시그모이드 함수의 단점
그래디언트 소실 문제(Vanishing Gradient Problem): 시그모이드 함수는 입력값이 크거나 작을 경우, 그래디언트 값이 매우 작아져서 학습이 어려워지는 문제가 발생할 수 있습니다. 이로 인해 신경망이 더 깊어질수록 그래디언트 정보가 손실되어 학습이 제대로 이루어지지 않는 문제가 있습니다.
출력값 중심의 문제(Output Centered Problem): 시그모이드 함수는 출력값의 평균이 0.5로 중심이 되는 특징을 가지고 있습니다. 따라서, 데이터의 분포가 0.5로 중심이 되지 않는 경우, 신경망이 학습하지 못할 수 있습니다.
시그모이드 함수 구현
numpy로 간단하게 구현
import numpy as np
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
x = np.array([1, 2, 3, 4, 5])
print(sigmoid(x))[0.73105858 0.88079708 0.95257413 0.98201379 0.99330715]
이 구현의 문제점은 오버플로우가 발생할 수 있어 수치적으로 안정적이지 않을 수 있다는 것입니다. 입력값이 양수의 경우 큰 문제가 없는데 음수의 경우 입력값이 클때 아래처럼 문제가 생기게 됩니다
x = np.array([9999999999, 2, 3, 4, 5])
print(x < 0)
print(sigmoid(x))[False False False False False]
[1. 0.88079708 0.95257413 0.98201379 0.99330715]
x = np.array([-9999999999, 2, 3, 4, 5]) # -9999999999 overflow
print(x < 0)
print(sigmoid(x))[ True False False False False]
[0. 0.88079708 0.95257413 0.98201379 0.99330715]
RuntimeWarning: overflow encountered in exp return 1 / (1 + np.exp(-x))
안정적인 시그모이드 함수 구현
방법1
def stable_sigmoid(x):
nx = np.array(x) # 정수,실수로 x가 들어왔을때 오류나지 않도록 타입변환
# x >=0 , x < 0 요소들 분리
pos_mask = (nx >= 0)
neg_mask = (nx < 0)
z = np.zeros_like(nx,dtype=float)
z[pos_mask] = np.exp(-nx[pos_mask])
z[neg_mask] = np.exp(nx[neg_mask])
# 분모(top)
top = np.ones_like(x,dtype=float)
top[neg_mask] = z[neg_mask]
return top / (1 + z)x가 양수이면 단순히 1 / (1 + np.exp(-x))를 사용하지만 x가 음수이면 대신 np.exp(x) / (1 + np.exp(x)) 함수를 사용합니다.
x 를 하나의 입력값 뿐만 아니라 넘파이 배열로도 받을 수 있도록 처리되었습니다.
요소 x 가
x >=0 : 1 / (1 + np.exp(-x))
x < 0 : np.exp(x) / (1 + np.exp(x))
로 계산합니다.
다음과 같이 더이상 오버플로우 오류가 나지 않는 것을 확인 할 수 있습니다.
print(stable_sigmoid(np.array([-9999999999, 2, 3, 4, 5])))
print(stable_sigmoid(-9999999999))[0. 0.88079708 0.95257413 0.98201379 0.99330715]
0.0
방법2
방식은 약간 다르지만 좀더 간단한 구현은 아래와 같습니다.
import numpy as np
def stable_sigmoid(x):
return np.exp(-np.logaddexp(0., -x))logaddexp는 log(exp(x1) + exp(x2)) 를 계산합니다. 이 함수는 계산된 사건의 확률이 일반 부동 소수점 숫자의 범위를 초과할 정도로 작을 수 있는 통계에 유용합니다.
print(stable_sigmoid(np.array([-9999999999, 2, 3, 4, 5])))
print(stable_sigmoid(-9999999999))[0. 0.88079708 0.95257413 0.98201379 0.99330715]
0.0
matplotlib로 시각화
import matplotlib.pylab as plt
#그래프 그러보기
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()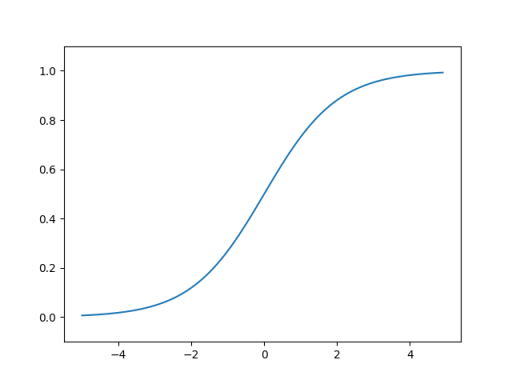
Reference

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>