@senspond
>
파이토치(torch) 기본 함수와 Tensor 클래스의 메소드 정리
파이토치(torch) 기본 함수와 Tensor 클래스의 메소드들을 정리해 본 글입니다. 워낙 종류가 많아서 전부 다 정리할 수는 없지만 자주 사용하는 것들을 추려서 정리해봤습니다.
torch 기본 함수와 Tensor 클래스의 메소드 정리
딥러닝을 위해 파이토치를 접하다 보면 햇갈리게 만드는 메소드와 함수들이 있습니다.
한가지 예시를 들어보겠습니다.
아래는 리스트, 넘파이 배열 형태를 Tensor 객체로 바꾸는 예시!!
a = [1,2,3]
b = np.array([4,5,6], dtype=np.int32)
# list -> tensor
t_a = torch.tensor(a)
# numpy -> tensor
t_b = torch.from_numpy(b)
print(t_a)
print(t_b)tensor([1, 2, 3])
tensor([4, 5, 6], dtype=torch.int32)
그런데 tensor 함수에 입력 자료형을 Any형태로 받을 수가 있어서
넘파이 배열도 Tensor 로 변환할 수 있습니다.
b = np.array([4,5,6], dtype=np.int32)
t_b = torch.tensor(b) # 가능
t_b = torch.from_numpy(b)그럼 tensor 하나로 그냥 쓰면 되지 from_numpy는 왜 또 따로 있고... 차이점이 뭐냐?
tensor
입력 자료형을 tensore 자료형으로 변환하는 함수 , 새 메모리를 할당
from_numpy
넘파이배열 자료형을 tensor 자료형으로 변환하는 함수 , 원래 메모리를 상속
is_tensor
tensor 자료형인지 아닌지를 확인
torch.is_tensor(a), torch.is_tensor(t_a)(False, True)
to
Tensor 객체의 dtype, device 를 변경할 수 있는 메소드
Tensor 객체의 dtype 을 변경
t_a = torch.tensor([1,2,3])
t_a_new = t_a.to(torch.float16)
print(t_a_new)tensor([1., 2., 3.], dtype=torch.float16)
Tensor 객체의 device를 변경
cuda0 = torch.device('cuda:0')
t_a.to(cuda0)tensor([1., 2., 3.], device='cuda:0')
Tensor 객체의 dtype 과 device를 변경
cuda0 = torch.device('cuda:0')
t_a.to(dtype=torch.float16, device=cuda0)tensor([1., 2., 3.], device='cuda:0', dtype=torch.float16)
ones, zeros
( ones : 1 , zeros : 0 ) 로 채워서 tensor 로 반환하는 함수
t_ones = torch.ones(2,3)
t_zeros = torch.zeros(2,3)
t_ones, t_zeros tensor([[1., 1., 1.], [1., 1., 1.]])
tensor([[0., 0., 0.], [0., 0., 0.]])
rand_tensor = torch.rand(2,3)
print(rand_tensor)tensor([[0.9072, 0.1058, 0.7239], [0.5551, 0.0136, 0.2714]])
reshape, view
tensor의 모양 변환
t = torch.zeros(30)
t.reshape(5, 6)tensor([[0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.]])
t = torch.zeros(30)
t.view(5, 6)tensor([[0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0.]])
[Pytorch] Tensor에서 혼동되는 여러 메서드와 함수 - Subinium의 코딩일지
view는 기존의 데이터와 같은 메모리 공간을 공유하며 stride 크기만 변경하여 보여주기만 다르게 한다.그래서
contigious해야만 동작하며, 아닌 경우 에러가 발생
reshape은 가능하면 input의view를 반환하고, 안되면 contiguous한 tensor로 copy하고 view를 반환
view는 메모리가 기존 Tensor와 동일한 메모리를 공유하는게 보장되지만 reshape은 그렇지 않다.
안전하게 형태만 바꾸고 싶다
reshape메모리가 공유되어 업데이트에 대한 보장이 이뤄진다
view(단 continguous하지 않은 경우 에러 발생가능)
transpose
두 개의 차원을 맞교환
함수 형태로도 있고 메소드 형태로도 동일한 이름으로 존재한다.
편의성을 위한 것인지 몰라도 이런 경우가 많다. 위의 reshape도 마찬가지이고 아래 permute 등도 마찬가지이다.
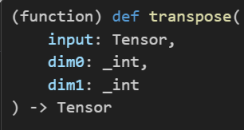
t = torch.zeros(30).reshape(5, 6)
# torch의 함수(transpose)
t_tr = torch.transpose(t, 0,1)
print(t.shape, '--->', t_tr.shape)torch.Size([5, 6]) ---> torch.Size([6, 5])
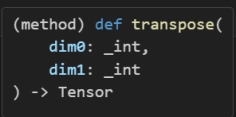
t = torch.zeros(30).reshape(5, 6)
# tensor의 메소드(transpose)
t_tr = t1.transpose(0, 1)
print(t.shape, '--->', t_tr.shape)torch.Size([5, 6]) ---> torch.Size([6, 5])
permute
transpose()는 딱 두 개의 차원을 맞교환 할 수 있는 반면, permute()는 모든 차원들을 맞교환 가능
x = torch.rand(16, 32, 3)
y = x.tranpose(0, 2) # [3, 32, 16]
z = x.permute(2, 1, 0) # [3, 32, 16]squeeze
차원 제거. 따로 차원을 설정하지 않으면 1인 차원을 모두 제거한다.
만약 차원을 설정해주면 그 차원만 제거한다.
(function) def squeeze(
input: Tensor,
dim: _int
) -> Tensortensor 의 메소드 형태도 있다.
(method) def squeeze(dim: _int) -> Tensor예시
x = torch.rand(1, 1, 20, 128)
x = x.squeeze() # [1, 1, 20, 128] -> [20, 128]
x2 = torch.rand(1, 1, 20, 128)
x2 = x2.squeeze(dim=1) # [1, 1, 20, 128] -> [1, 20, 128]t = torch.zeros(1,2,1,4,1)
t_sqz = torch.squeeze(t,2)
print(t.shape, '-->', t_sqz.shape)torch.Size([1, 2, 1, 4, 1]) --> torch.Size([1, 2, 4, 1])
unsqueeze
1인 차원을 생성. 어디에 1인 차원을 생성할 반드시 지정해주어야 한다
x = torch.rand(3, 20, 128)
x0 = x.unsqueeze(dim=0) #[3, 20, 128] -> [3, 1, 20, 128]
x1 = x.unsqueeze(1)
x2 = x.unsqueeze(2)
print(f"{x.shape} --> {x0.shape}")
print(f"{x.shape} --> {x1.shape}")
print(f"{x.shape} --> {x2.shape}")torch.Size([3, 20, 128]) --> torch.Size([1, 3, 20, 128])
torch.Size([3, 20, 128]) --> torch.Size([3, 1, 20, 128])
torch.Size([3, 20, 128]) --> torch.Size([3, 20, 1, 128])
normal
정규분포 생성
torch.manual_seed(1)
t1 = 2 * torch.rand(5,2) - 1
t2 = torch.normal(mean=0, std=1, size=(5,2))
t1, t2tensor([[ 0.5153, -0.4414], [-0.1939, 0.4694], [-0.9414, 0.5997], [-0.2057, 0.5087], [ 0.1390, -0.1224]]), tensor([[ 0.8590, 0.7056], [-0.3406, -1.2720], [-1.1948, 0.0250], [-0.7627, 1.3969], [-0.3245, 0.2879]])
multiply
곱
아래 예시를 보면 t1 * t2 한 것과 같은 것을 볼 수가 있다.
t1 * t2, torch.multiply(t1,t2)tensor([[ 0.4426, -0.3114], [ 0.0660, -0.5970], [ 1.1249, 0.0150], [ 0.1569, 0.7107], [-0.0451, -0.0352]]), tensor([[ 0.4426, -0.3114], [ 0.0660, -0.5970], [ 1.1249, 0.0150], [ 0.1569, 0.7107], [-0.0451, -0.0352]])
matmul
내적연산
t5 = torch.matmul(t1, torch.transpose(t2, 0, 1))
print(t5)tensor([[ 0.1312, 0.3860, -0.6267, -1.0096, -0.2943], [ 0.1647, -0.5310, 0.2434, 0.8035, 0.1980], [-0.3855, -0.4422, 1.1399, 1.5558, 0.4781], [ 0.1822, -0.5771, 0.2585, 0.8676, 0.2132], [ 0.0330, 0.1084, -0.1692, -0.2771, -0.0804]])
넘파이 처럼 @ 연산자를 사용 할 수도 있다.
t1 @ torch.transpose(t2, 0, 1)tensor([[ 0.1312, 0.3860, -0.6267, -1.0096, -0.2943], [ 0.1647, -0.5310, 0.2434, 0.8035, 0.1980], [-0.3855, -0.4422, 1.1399, 1.5558, 0.4781], [ 0.1822, -0.5771, 0.2585, 0.8676, 0.2132], [ 0.0330, 0.1084, -0.1692, -0.2771, -0.0804]])
참고자료
[Pytorch] Tensor에서 혼동되는 여러 메서드와 함수 - Subinium의 코딩일지

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>