@senspond
>
DCGAN 모델로 128x128 이미지 생성하고 업스케일링, GFPGAN으로 보정
DCGAN 모델로 128x128 이미지 생성하고 업스케일링, GFPGAN으로 보정
딥러닝을 통해 이미지를 생성을 해보고 싶었다. 생성형 AI에는 가장 기본적인 GAN 생성모델이라는 것이 있는데, 책이나 온라인 예제들이 GAN 생성모델 32x32 MNIST 손글씨 이미지와 64x64 celeba 예제밖에 없었다.
그런 것들은 너무 식상해서 스테이블 디퓨전으로 직접 생성한 한국 미소녀 얼굴 이미지들로 학습을 시켜봤는데, 데이터가 너무 소량이다 보니 학습이 정상적으로 되지 않았다. 한 이미지 1000장 정도는 만들어야 학습을 시킬 수 있는 것 같다.
그리고 64x64 가 아니라 좀 더 고해상도의 이미지를 생성해보고 싶었다. 그런데 400 이상 사이즈를 해보려니 너무 오래 걸려서 이거 학습 시키느라 컴퓨터를 켜놓고 한동안 아무것도 못할 것 같았다.
그래서 우선 celeba 데이터 셋을 128x128 사이즈로 리사이징 후 학습을 진행해보았다.
학습 데이터셋 로드
웃는 얼굴 celeba 데이터 셋을 (128,128) 사이즈로 잘라서 준비했다.
image_size = 128
dataroot = "./"
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# Plot some training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
DCGAN
DCGAN은 GAN 과 Convolution 합성곱으로 이루어진 GAN모델이다. 최초로 고화질의 이미지를 만들어 내기 시작한 GAN 모델이라고 한다. 자세한 설명은 나중에 따로 정리해보기로 하겠다.
생성망
class Generator (nn.Module):
""" 생성망 """
def __init__ (self, z_dim, img_channels):
super (Generator, self).__init__ ()
# Input: N x z_dim x 1 x 1
self.gen = nn.Sequential (
self._block (z_dim, 1024, 4, 2, 0),
self._block (1024, 512, 4, 2, 1),
self._block (512, 256, 4, 2, 1),
self._block (256, 128, 4, 2, 1),
self._block (128, 64, 4, 2, 1),
nn.ConvTranspose2d (64, img_channels, kernel_size = 4, stride = 2, padding = 1),
nn.Tanh ()
)
def _block (self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential (
nn.ConvTranspose2d (in_channels, out_channels, kernel_size, stride, padding, bias = False),
nn.BatchNorm2d (out_channels),
nn.ReLU ()
)
def forward (self, x):
return self.gen (x)판별망
class Discriminator (nn.Module):
""" 판별 """
def __init__ (self, img_channels):
super (Discriminator, self).__init__ ()
# Input: N x channels_img x 128 x 128
self.disc = nn.Sequential (
nn.Conv2d (img_channels, 32, kernel_size = 4, stride = 2, padding = 1),
nn.LeakyReLU (0.2),
self._block(32, 64, 4, 2, 1),
self._block(64, 128, 4, 2, 1),
self._block(256, 512, 4, 2, 1),
self._block (512, 1024, 4, 2, 1),
nn.Conv2d (1024, 1, kernel_size = 4, stride = 2, padding = 0),
nn.Sigmoid ()
)
def _block (self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential (
nn.Conv2d (in_channels, out_channels, kernel_size, stride, padding, bias = False),
nn.BatchNorm2d (out_channels),
nn.LeakyReLU (0.2)
)
def forward (self, x):
return self.disc (x)
칼라 이미지 이기 때문에 in_channels 에 3 이 들어가야 한다. (R,G,B)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)그리고 초기 가중치를 정의하는 함수를 만들고 데이터 셋을 불러와 학습을 진행시켜 보았다.
결과
5epoche
5회 학습을 하는데도 상당한 시간이 걸렸다. 이 데이터 셋으로 64x64 이미지를 학습 할 때보다 거의 6~8배 오래 걸리는 것 같다.

10epoche
5epoche 이후에 더 이상 제대로 학습이 되지 않아 성능 차이가 발생하지 않았다.
5epoche까지 정상적으로 학습이 진행되며 G와 D가 수렴을 하다가 좀 더 학습 시키니 갑자기 G와 D의 균형이 깨지면서 정상적인 학습이 되지 않았다. GAN을 다뤄보면 데이터셋이 달라지거나 미세한 파라미터만 달라져도 이런 일들이 잘 발생되어 어려움이 있었는데, 왜 이런 문제가 생기는지에 대해서는 좀 더 생각해봐야 겠다.
모델 저장/이미지 생성
# 모델 저장
# 판별자 모델
torch.save(netD,'./128_net_d_5.pth')
# 생성자 모델
torch.save(netG,'./128_net_g_5.pth')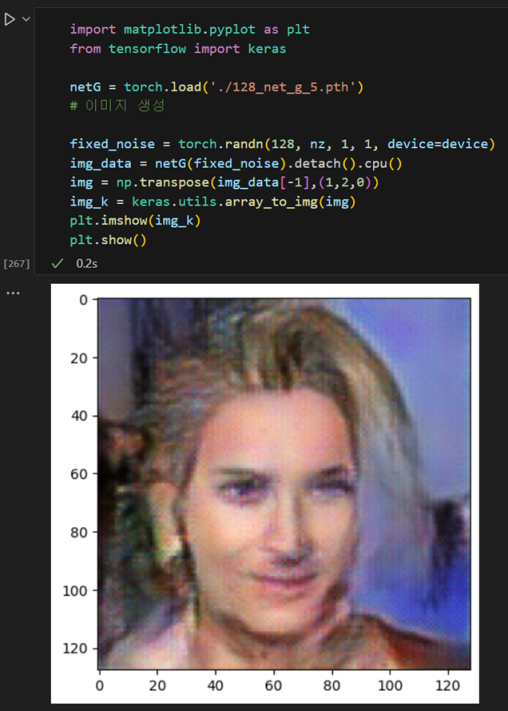
DCGAN + GFPGAN
이 5회 학습된 DCGAN 모델로 128x128 이미지를 생성하고 그나마 잘 뽑힌 이미지를 가지고
1024x1024 사이즈로 업스케일링 후 GFPGAN으로 후보정을 해보았다.
스테이블 디퓨전으로 AI그림 그릴때도 GFPGAN을 플러그인으로 넣고 후보정을 해서 얼굴보정을 시키고는 했었는데.. 여기에 해보면 어떻게 나올 지 궁금했다.
1024x1024 업스케일링
업스케일링이라고 했지만... DCGAN으로 생성된 128x128 이미지 사이즈를 그냥 8배 늘려버렸다.
128 사이즈를 보다 정교하게 만들어 낼 수 있고 최대한 이미지 화질 저하 없이 업스케일링 할 수 있다면 좀더 좋을 것 같다.
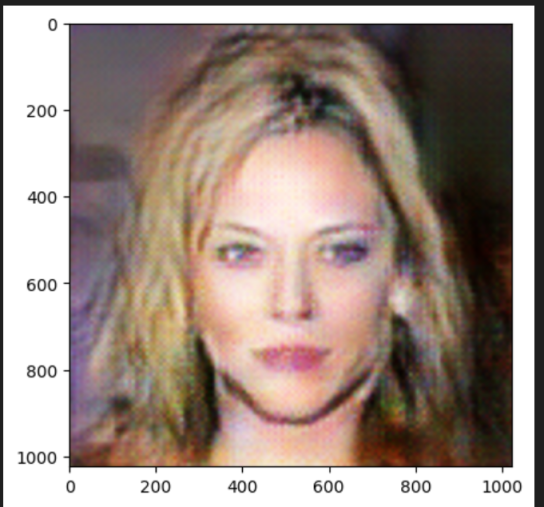
GFPGAN으로 후처리
여기서는 사전학습된 GFPGAN 1.3 모델을 받아 추론을 했다.
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth

생성된 1024x1024 이미지
GFPGAN이 얼굴 디테일을 살펴주는 모델이다보니... 얼굴 외 부분들은 그대로.... ㅎㅎ
결론
여러 시도를 해보며 처음부터 GAN으로 고해상도 이미지를 뽑아내기는 상당한 난이도와... 컴퓨팅 자원이 필요하다는 것을 느끼게 되었다. 그 방법보다는 작은 사이즈의 이미지를 만들어서 되도록 손실 없이 업스케일링 하고 적절하게 후처리를 하는 방식으로 고해상도 이미지를 생성하는 방법이 보다 접근하기가 쉬울 것 같다는 생각이 들었고 좀더 연구해봐야 겠다.

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>