@senspond
>
GAN의 문제점과 PGGAN 논문 리뷰
PGGAN이라는 논문을 읽고 공부한 내용을 정리해 본 글입니다.
GAN으로 고해상도 이미지를 생성하는 것은 상당한 난이도가 있는 분야인 것 같다.
그리고 직접 학습을 시켜서 구현해보려면 상당한 컴퓨팅 자원이 있어야 하는 문제도 있다.
개인적으로 나는 생성형 AI에 많은 관심을 가지고 있기 때문에, GAN 기반의 기술들에 관심을 가지고 있다.
오늘은 PGGAN이라는 논문을 읽고 공부한 내용을 정리해본다. PGGAN은 고해상도 이미지를 생성할 수 있는 StyleGAN의 베이스 기술이 되기도 한다.
[2105.02201] PD-GAN: Probabilistic Diverse GAN for Image Inpainting (arxiv.org)
PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
GAN의 문제점
1. Unstable training
real distribution과 fake distribution들이 겹치는 부분(overlap)이 적다면, 이 분포들 간의 거리를 측정할 때 gradient는 random한 방향을 가리킬 수가 있음.
2. Mode collapse
enerated distribution이 실제 데이터의 분포를 모두 커버하지 못하고 다양성을 잃어버리는 현상.
G는 그저 loss만을 줄이려고 학습을 하기 때문에 전체 데이터 분포를 찾지 못하게 되고, 결국에는 하나의 mode에만 강하게 몰리게 되는 경우를 의미
3. Easy discrimination of high-resolution images
고해상도의 이미지(high-resolution images)를 생성할 수록, 가짜 이미지라고 판별하기 쉬워지는 현상
왜냐하면, 처음에 생성하는 fake 이미지와 real 이미지의 차이가 너무 크기 때문에 양질의 gradient 를 얻기가 어려워짐
4. Small batch size during training of high-resolution GANS
고해상도의 이미지를 만들기 위해서는 더 작은 미니 배치를 사용해야 하는데, 훈련 안정성이 떨어질 수 밖에 없는 문제
PGGAN (Progressive Growing of GANs)
Idea
이러한 GAN의 문제점들을 해결하기 위해 PGGAN에서는 Generator와 Discriminator를 점진적으로 학습.
즉, 만들기 쉬운 low-resolution부터 시작하여 새로운 layer를 조금씩 추가하고 higher-resolution의 detail들을 생성한다.
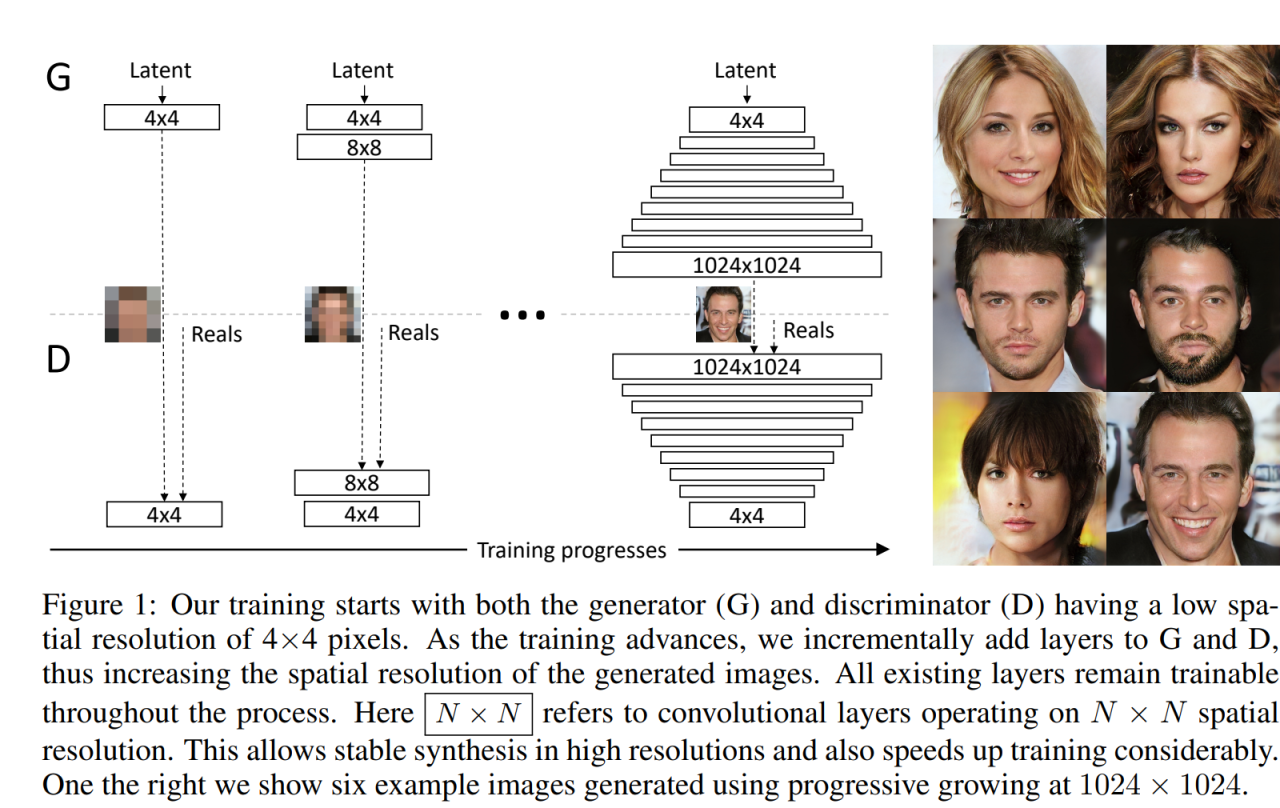
핵심적인 아이디어는 점진적으로 해상도를 높여가며 학습하자는 것이고,
그 외 정리하자면 크게 4가지 아이디어가 있다.
1. Progressive Growing
- 점진적으로 해상도를 높여가며 학습
2. PixelNorm
- 기존에 많이 쓰이는 BatchNorm(배치정규화)와는 달리 픽셀별로 Normalization 작업을 수행
3. Equalized Learning Rate
- 가중치를 sqrt(2/입력개수)로 나누어 모든 가중치가 동일한 속도로 학습될 수 있도록 한다.
4. Minibatch Std
- Discriminator의 마지막 블록에 해당 레이어를 추가하여 모드 붕괴 현상을 완화
Benefits
이러한 방식은 몇 가지 장점이 있다.
More Stable Training : more steps done at lower resolution with larger minibatches
low-resolution의 이미지를 학습하면 class information도 적고 mode도 몇개 없기 때문에 안정적
Faster training : 2 - 6 x faster
lower resolution에서부터 비교하여 학습을 하기 때문에 학습속도가 2-6배나 빨라진다.
Training avoids high resolution problem of too much divergence early on
초반에 고해상도 이미지를 학습하는데 발산으로 인해 학습을 실패하는 경우를 회피할 수 있음
Only use a single GAN instead of a hierarchy of GANs
하나의 GAN으로도 좋은 성능 가능
Fading in higher resolution layers
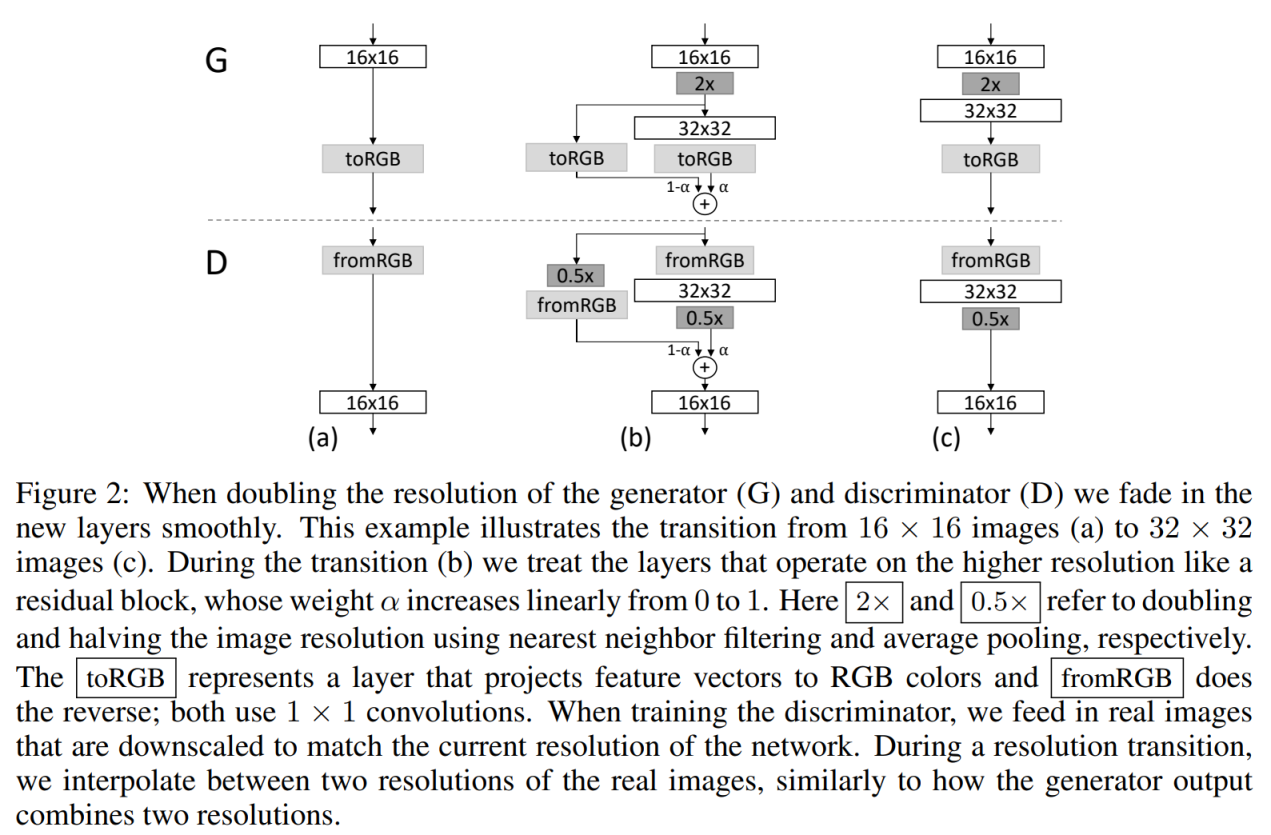
low-resolution부터 시작하여 새로운 layer를 조금씩 추가하고 higher-resolution의 이미지를 생성해 나가는것이 PGGAN의 핵심 아이디어라고 했다. 그것을 어떤식으로 제시했는지에 대한 설명이다.
개인적으로 이해하기 상당히 어려운 내용이었는데, 내가 이해한 내용은 다음과 같다.
왜 이런 복잡한 구조를 가지게 되었는가 ?
16x16 해상도를 바로 2배 업스케일링하여 32x32 레이어에서 새로운 이미지를 생성하게 되면 정상적으로 학습이 진행되지 않는 다는 것이 문제였던 것이다. 그렇게 간단하게 해결되는 문제였다면 이런 복잡한 구조를 만들어 낼 필요가 전혀 없었을 것이다.
따라서 부드럽게 레이어를 끼어넣어 점진적으로 학습시키기 위해서 fade in 이라는 방법을 제시한다.
a) -> b) 16x16 해상도를 학습 후 32x32 레이어를 끼어넣을 때 ,
생성망이 만들어낸 16x16 이미지를 2x (2배 업스케일링) 한 이미지와 , 32x32 컨볼루션 레이어에서 새롭게 만들어낸 이미지와 합치게 된다. 해상도 전환 중에 두 해상도 사이를 보간하여 결합하게 되는데, 0~1 사이의 값을 가지는 알파(alpha) 값에 따라 (1-a) : a 의 비율로 합쳐지게 된다.
판멸망에서는 0.5x ( 가장 가까운 이웃 필터링과 평균 풀링을 각각 사용하여 이미지 해상도를 절반으로 줄여서) 실제 이미지와 비교하여 판별하게 된다.
점진적으로 학습이 진행됨에 따라 alpha 값은 선형적으로 0 에서 1까지 도달하게 되고,
그림 c) 처럼 되면서 순수하게 32x32 레이어에서 생성하는 이미지를 가지고 판별하게 된다.
이런식으로 a)->b)->c)->b)->c) .... 의 과정을 거치면서 점진적으로 새로운 레이어를 추가해가면서
고해상도의 이미지를 생성하고 판별할 수 있는 G와 D를 학습시켜 나갈 수 있다는 것.
toRGB : 특징 벡터를 RGB 색상으로 투영하는 레이어 ( 1x1 컨볼루션 레이어)
fromRGB : toRGB의 반대 ( 1x1 컨볼루션 레이어)
Architecture
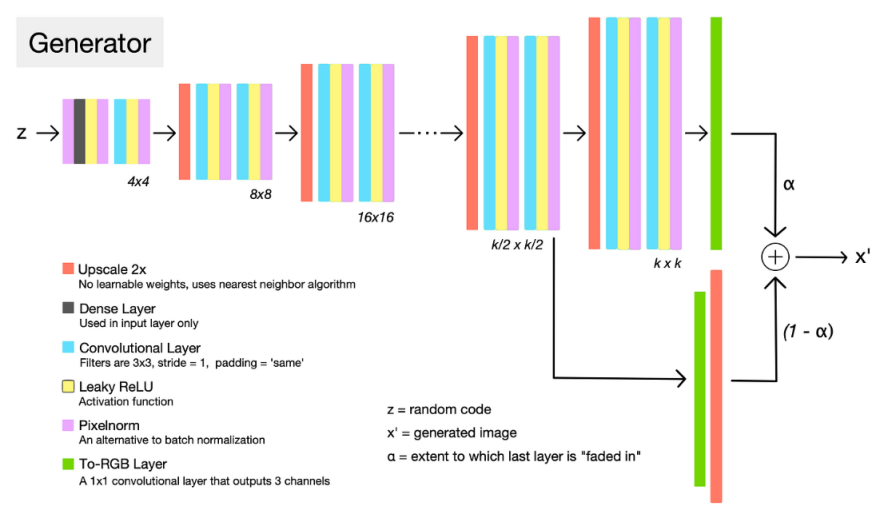
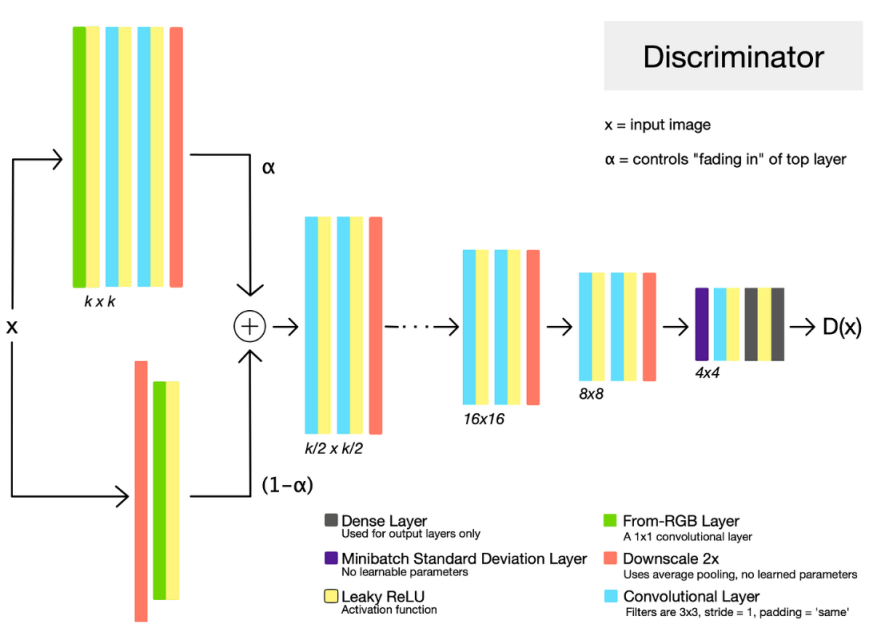
Training Time
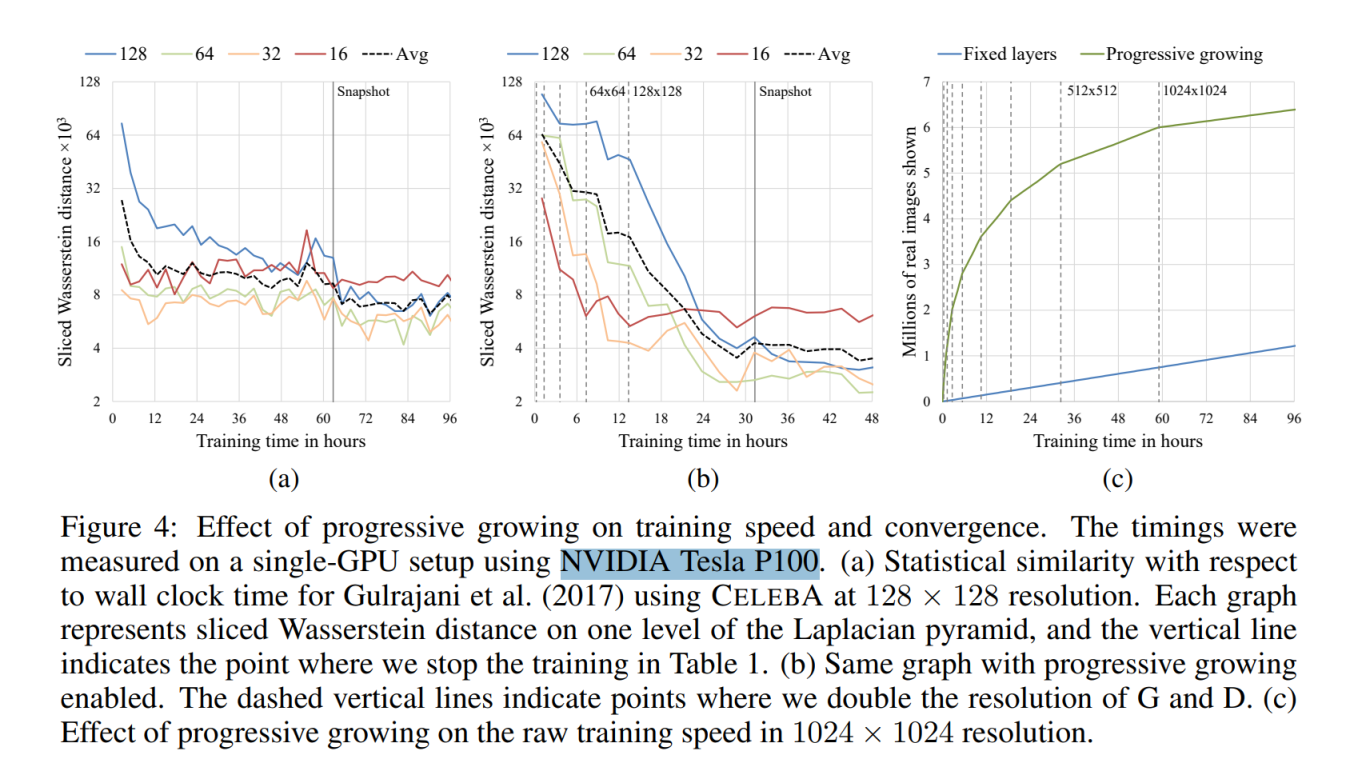
1024x1024 이미지를 학습 시키는데, Tesla P100으로 13일이 걸렸다고 한다. 기존 방식보다 2 ~ 6배 정도 빠르다고 하는데도 이 정도면 기존 방식으로는 몇달 씩 컴퓨터 돌려놓고 있어야 할 것 같다...
아쉽지만 이 실습도 좀 작은 해상도로 해봐야 할 것 같다.
레퍼런스
DCGAN : [1511.06434] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (arxiv.org)
PGGAN : [1710.10196] Progressive Growing of GANs for Improved Quality, Stability, and Variation (arxiv.org)
Progressive Growing of GANs for Improved Quality, Stability, and Variation - HackMD
deepsound-project/pggan-pytorch: Progressively Growing GAN in PyTorch for Image and Sound generation (github.com)

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>