@senspond
>
Fashion MNIST MLP, CNN, LSTM, CNN-LSTM 등 6가지 모델로 이미지 분류해보기
Fashion MNIST MLP, CNN, LSTM, CNN-LSTM 등 6가지 모델로 이미지 분류해보고 적어본 실험 내용입니다.
딥러닝에 입문해서 이미지 분류를 공부할 때 거쳐가는 과정이 있다. 거의 대부분 책들에서 CNN을 처음 설명하고 바로 처음 등장하는 손글씨 있는 MNIST. 그런데 성능이 너무 좋게 나오다보니 시시해서 그 담에 Fashion MINST등 조금씩 더 난이도를 높여가며 하게 되는 것 같다.
아래는 공부를 할 때 많이 사용되는 이미지 데이터셋 목록들이다.
| 해상도 | 클래스 개수 | 학습 데이터 수 | 테스트 데이터 수 |
CIFAR-10 | 32 X 32 X 3 | 10개 | 50,000개 (클래스당 5,000개) | 10,000개 (클래스당 1,000개) |
CIFAR-100 | 32 X 32 X 3 | 100개 | 50,000개 (클래스당 500개) | 10,000개 (클래스당 100개) |
STL-10 | 96 X 96 X 3 | 10개 | 5,000개 (클래스당 500개) | 8,000개 (클래스당 800개) |
MNIST | 28 X 28 X 1 | 10개 | 60,000개 | 10,000개 |
FASHION-MNIST | 28 X 28 X 1 | 10개 | 60,000개 | 10,000개 |
SVHN | 32 X 32 X 3 | 10개 | 73,257개 | 26,032개 |
그런데 이미지 분류를 순수 순환신경망(RNN)으로도 할 수가 있다. 마치 컨볼루션신경망(CNN)을 쓰지 않고 다층퍼셉트론(MLP)으로도 이미지 분류를 할 수 있는 것처럼 말이다.
보통 CNN은 컴퓨터 비전분야에서 쓰이고 RNN은 자연어처리나 시계열 데이터를 예측하는데 쓴다고 배우고.. 나 또한 그렇게만 알고 이었는데, CNN이 자연어 처리분야에서 사용되기도 하고 RNN이 컴퓨터비전에서 사용 될 수가 있다는 것이였다.
CNN 감성분류 참고: [1408.5882] Convolutional Neural Networks for Sentence Classification (arxiv.org)
그리고 CNN과 RNN을 결합한 모델이 자연어처리분야에서도 사용될 수도 있고, 컴퓨터비전쪽에서도 사용 될 수가 있다. 논문들을 살펴보면 기존 CNN 이미지 분류에서도 LSTM을 결합한 형태의 논문들도 볼 수가 있고 보다 좋은 성능을 내주었다는 연구 결과 등도 볼 수가 있었다. ( VGG16에 LSTM을 결합한 예시 등)
아무튼 Fashion MNIST 데이터 셋을 가지고 이미지 분류를 여러 모델을 만들어서 30회씩 돌려 보았다. 책에만 나와있는 예제를 그대로만 따라하는 것은 재미가 없기도 하고 별로 도움이 되지 않는 공부 방법인 것 같다. 그런데 모델 이렇게도 만들어보고 저렇게도 만들어보고 돌려 보다보면.... 시간이 정말 훌쩍 가는 것 같다.
준비
Import
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.callbacks import EarlyStopping, TensorBoard, ModelCheckpoint
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, LSTM, BatchNormalization, \
LayerNormalization, Dropout, Dense, Input, LayerNormalization, Flatten, TimeDistributed
import numpy as np
import matplotlib.pyplot as plt
import random
import os
print(tf.__version__)시드고정
def seed_everything(seed=42):
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
seed_everything()데이터셋 불러오기
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
전처리
train_images = train_images / 255.0
test_images = test_images / 255.0이미지 픽셀은 0~255 범위의 값을 가지기에 255로 나눠주면 0~1 구간으로 스케일링이 된다.
훈련/평가 함수 정의
# 모델 컴파일하고 훈련
def model_cfit(model, batch_size, epochs, checkpoint):
log_dir= os.path.join(os.getcwd(), 'logs', datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
early_stop = EarlyStopping(monitor='val_loss', patience=20)
tensorboard= TensorBoard(log_dir=log_dir, histogram_freq=1)
checkpoint = ModelCheckpoint(checkpoint, monitor='val_loss', verbose=0, save_best_only=True, mode='auto' )
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
hist = model.fit(train_images, train_labels,
batch_size=batch_size,
validation_split = 0.2,
epochs=epochs,
callbacks=[early_stop,tensorboard, checkpoint])
return hist
# 모델 평가
def model_eval(model, checkpoint=None):
if checkpoint is not None:
model.load_weights(checkpoint)
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'test_acc : {test_acc}, test_loss: {test_loss}')
# 평가지표 시각화
def visualization(hist):
fig, ax = plt.subplots(1, 2, figsize=(15,5))
ax[0].set_title('loss')
ax[0].plot(hist.history['loss'])
ax[0].plot(hist.history['val_loss'])
ax[1].set_title('accuracy')
ax[1].plot(hist.history['accuracy'])
ax[1].plot(hist.history['val_accuracy'])
plt.show()모델정의
모델1(MLP)
단순한 멀티 레이어 퍼셉트론이다.
def mlp_model():
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(256, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
return model모델2(CNN)
간단한 CNN모델이다. LSTM, CNN-LSTM과 비교하기 용으로 적당하게 구성했다.
def cnn_model():
model = Sequential([
Conv2D(32, (3, 3), padding="SAME", activation='relu', input_shape=(28, 28, 1)),
BatchNormalization(),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), padding="SAME", activation='relu'),
BatchNormalization(),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), padding="SAME", activation='relu'),
BatchNormalization(),
MaxPooling2D((2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
return model모델3(LSTM)
이미지 분류에도 LSTM모델을 활용할 수 있다. 여기서는 2차원 배열을 시계열 데이터로 바라보게 된다.
( 28x28 짜리 행렬은 28x1행렬이 28개인 시퀀스로 보고 timesteps가 28인 셈)
LSTM도 다층으로 구성하면 좀 더 성능이 올라가는 것을 확인할 수 있었는데, LSTM을 2층 정도로만 구성을 했다.
def lstm_model():
model = tf.keras.models.Sequential([
LSTM(64, input_shape=(28, 28), return_sequences=True),
LSTM(64, return_sequences=False),
LayerNormalization(),
Dropout(0.5),
Dense(10, activation='softmax')]
)
return model모델4(CNN-LSTM)
모델2(CNN)와 모델3(LSTM)이 합쳐진 구조로 만들었다.
def cnn_lstm_model():
model = Sequential([
# CNN
Conv2D(32, (3, 3), padding="SAME", activation='relu', input_shape=(28, 28, 1)),
BatchNormalization(),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), padding="SAME", activation='relu'),
BatchNormalization(),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), padding="SAME", activation='relu'),
BatchNormalization(),
MaxPooling2D((2, 2)),
# Flatten
TimeDistributed(Flatten()),
# LSTM
LSTM(64, return_sequences=True),
LSTM(64, return_sequences=False),
Dropout(0.5),
Dense(10, activation='softmax')
])
return modelCNN에서 LSTM으로 연결할 때 TimeDistributed를 Wrapper Layer로 감싸줘야 한다.
TimeDistributed는 시간의 조각(Temporal slice)을 만들어준다.
모델5(CNN)
먼가 앞의 CNN이 아쉬운 것 같아서 Kaggle을 참고해서 하나 더 만들었다.
def cnn2_model():
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', strides=1, padding='same'
, input_shape=(28,28,1)))
model.add(BatchNormalization())
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', strides=1, padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', strides=1, padding='same')
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model 모델6(CNN-LSTM)
def cnn2_lstm_model():
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', strides=1, padding='same', input_shape=(28,28,1)))
model.add(BatchNormalization())
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', strides=1, padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', strides=1, padding='same'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(512, return_sequences=True))
model.add(LayerNormalization())
model.add(Dropout(0.5))
model.add(LSTM(128, return_sequences=False))
model.add(LayerNormalization())
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model그냥 정말 단순하게 위 CNN모델에서 FC레이어의 Dense층만 LSTM으로 바꾸어보았다.
그리고 BatchNormalization 대신에 LayerNormalization를 사용했다.
결과
모델1(MLP)
mlp, mlp_hist = model_cfit(model=mlp_model(), batch_size=256, epochs=30, checkpoint="mlp.keras")
model_eval(mlp, "mlp.keras")313/313 - 0s - loss: 0.3276 - accuracy: 0.8865 - 254ms/epoch - 812us/step
test_acc : 0.8865000009536743, test_loss: 0.32755646109580994
visualization(mlp_hist)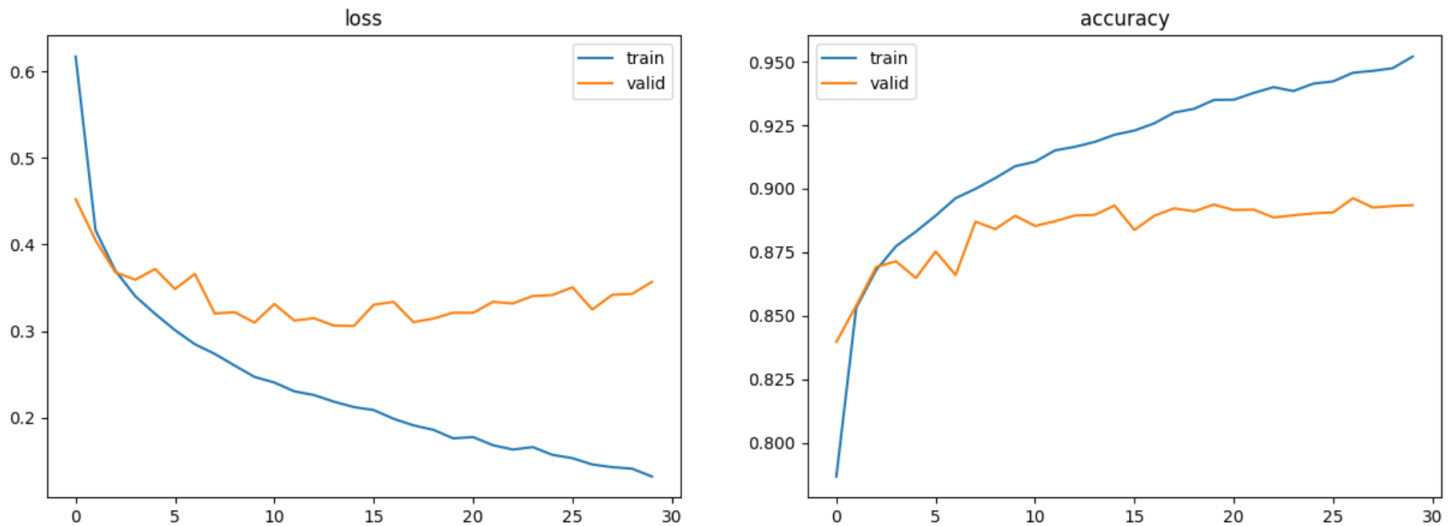
모델2(CNN)
model_eval(cnn, "cnn.keras")313/313 - 1s - loss: 0.2827 - accuracy: 0.9040 - 1s/epoch - 4ms/step
test_acc : 0.9039999842643738, test_loss: 0.28272369503974915
visualization(cnn_hist)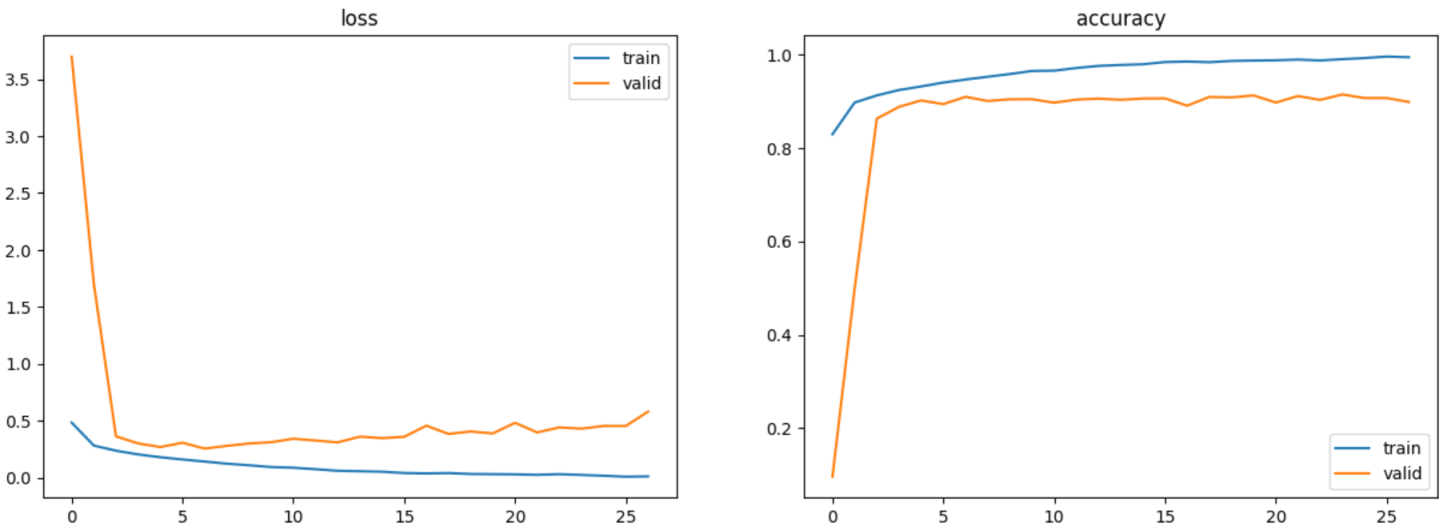
val_loss 그래프를 보니 loss가 줄어들다가 어느 순간 부터 증가하는 형태가 나타났다.
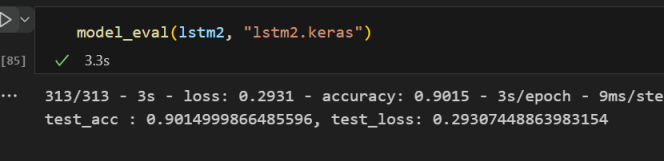
모델3(LSTM)
313/313 - 2s - loss: 0.3290 - accuracy: 0.8837 - 2s/epoch - 6ms/step
test_acc : 0.8837000131607056, test_loss: 0.3289940357208252
이 결과 이후 층을 늘리고 순수 LSTM모델로만 해봤는데, LSTM만으로도 fashion-MNIST 이미지 분류를 하는데 90% 이상 테스트 정확도가 나올 수 있었다. 그리고 이상하게 loss그래프를 보면 CNN보다 더 안정적인 형태가 나왔다. CNN모델로는 더 잘 설계를 해야 과적합을 피하며 더 예쁜 그래프가 그려질 것 같았다.
fashion-MNIST을 LSTM가지고 이미지 분류를 하는데 Heuristic Pattern Reduction과 Network Pruning 방법을 통해 시간 소모를 줄이면서도 효율적인 성능이 나오며 테스트 정확도 89.94% 달성할 수 있다고 쓴 논문이 있었는데,

LSTM: An Image Classification Model Based on Fashion-MNIST Dataset : sv-lncs (anu.edu.au)
더 해보니 대충 LSTM 3층으로 적당히 구성하고 30회 학습으로 달성 되었다. 좀 더 잘 만들면 더 높은 성능도 가능 할 것 같다.
모델4(CNN-LSTM)
모델2, 모델3 보다는 좋은 성능을 보여주었지만 학습 시키는데 모델2(CNN)에 비해서는 좀 더 걸렸다.
cnn_lstm, cnn_lstm_hist = model_cfit(model=cnn_lstm_model(), batch_size=256, epochs=30, checkpoint="cnn_lstm.keras")
model_eval(cnn_lstm, "cnn_lstm.keras")
313/313 - 1s - loss: 0.2571 - accuracy: 0.9148 - 949ms/epoch - 3ms/step
test_acc : 0.9147999882698059, test_loss: 0.2570796012878418
visualization(cnn_lstm_hist)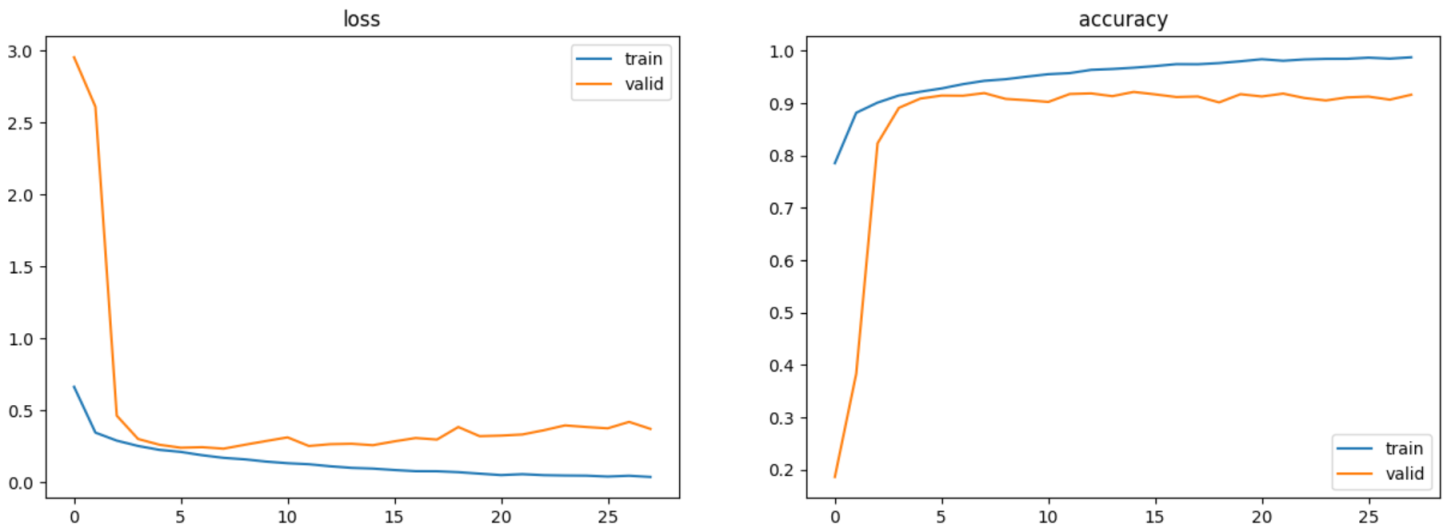
재미난 것은 모델2 베이스라 그런지 모델2(CNN)의 loss함수랑 비슷한 형태로 나왔다.
모델2에 비해 극적인 차이는 없었지만 좀 더 낳은 성능을 보여주는 것을 확인 할 수 있었다.
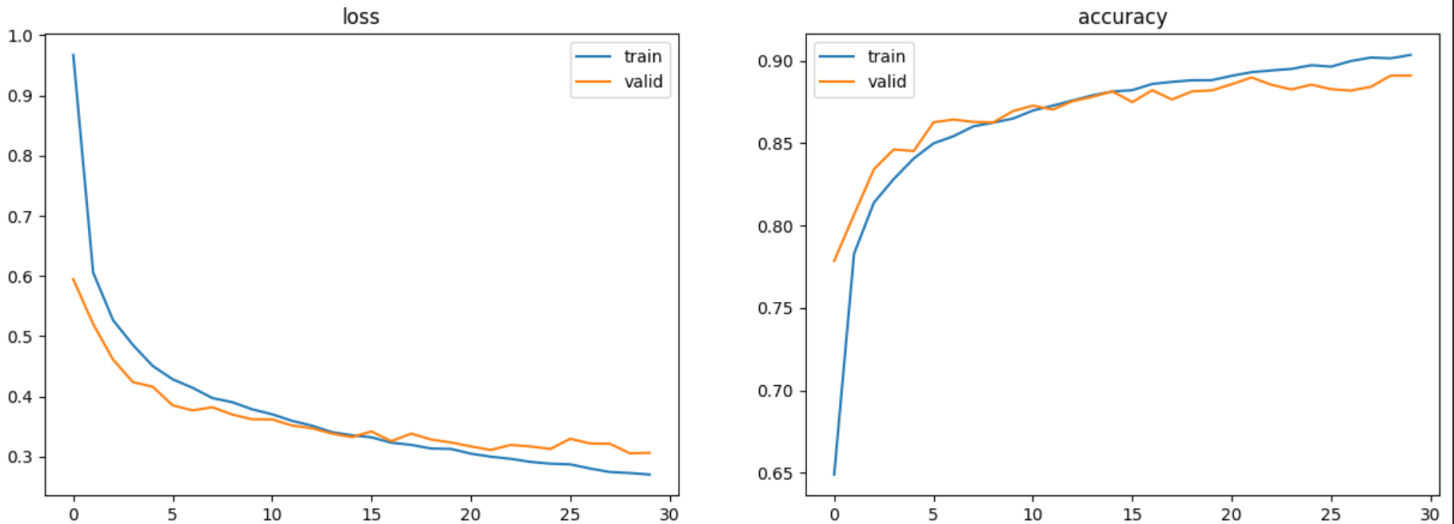
모델5(CNN)
좀더 복잡해진 CNN모델이다 보니 모델4(CNN-LSTM) 보다 1회 학습하는데 조금 더 시간이 더 걸렸다.
하지만 5 epoches 정도 만으로도 90% 가 넘는 val_accuracy를 보여주었다. 하지만 그 이후부터는 쉽게 올라가지 않았다.
cnn2, cnn2_hist = model_cfit(model=cnn2_model(), batch_size=256, epochs=30, checkpoint="cnn2.keras")
model_eval(cnn2, "cnn2.keras")313/313 - 1s - loss: 0.2162 - accuracy: 0.9300 - 1s/epoch - 4ms/step
test_acc : 0.9300000071525574, test_loss: 0.21618039906024933
visualization(cnn2_hist)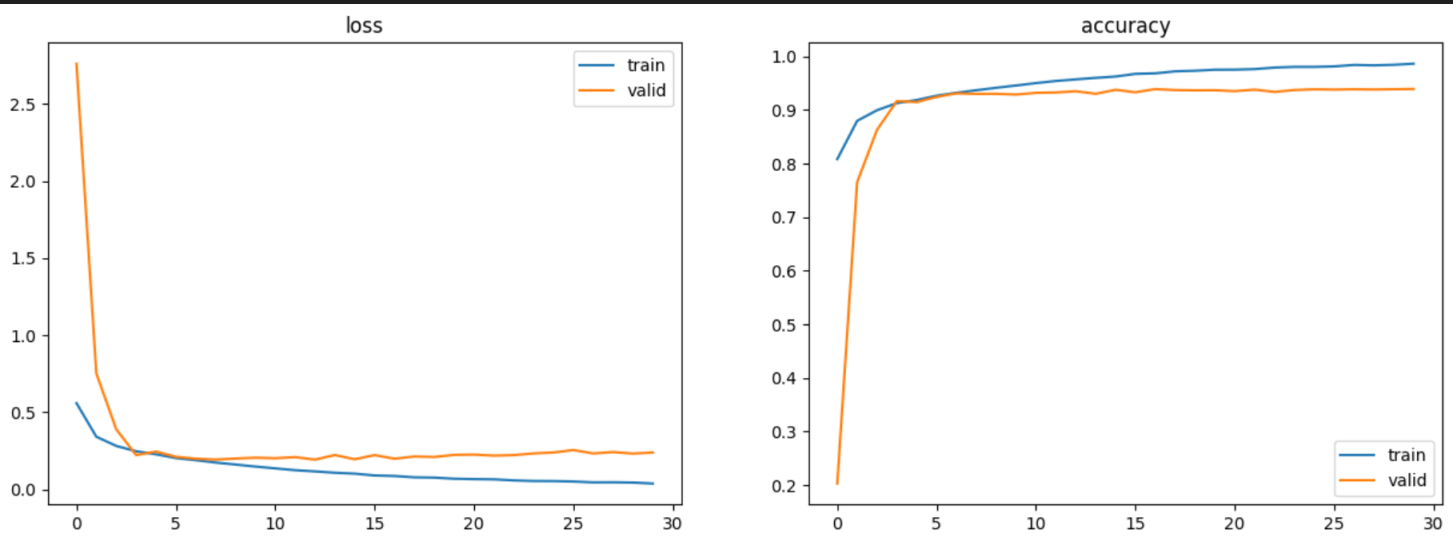
모델6(CNN-LSTM)
cnn2_lstm, cnn2_lstm_hist = model_cfit(model=cnn2_lstm_model(), batch_size=256, epochs=30, checkpoint="cnn2_lstm.keras")model_eval(cnn2_lstm, "cnn2_lstm.keras")313/313 - 2s - loss: 0.2203 - accuracy: 0.9251 - 2s/epoch - 5ms/step
test_acc : 0.9251000285148621, test_loss: 0.2202836126089096
visualization(cnn2_lstm_hist)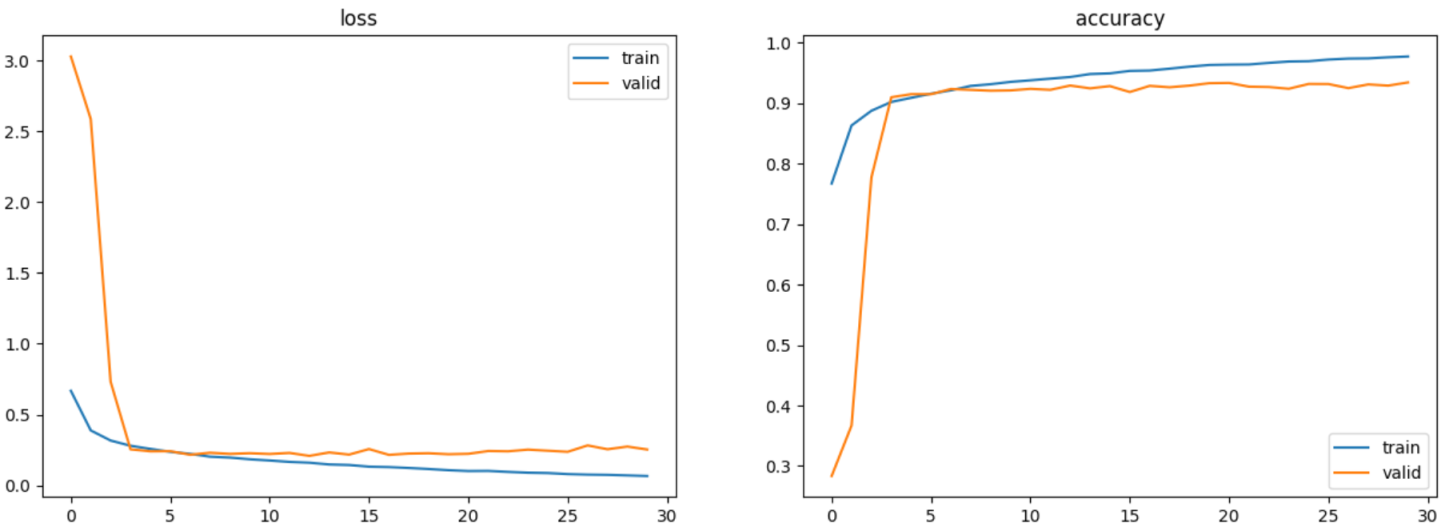
모델 5랑 거의 차이가 나지 않았고 그래프 형태도 비슷해졌다. 자세히 보면 loss가 감소하다 증가하는데 순수CNN보다 아주 미세하게 천천히 올라갔다.
결론
이 결과만 가지고는 일반화 할 수는 없지만 특정 경우에 LSTM이 이미지 분류하는데 CNN보다 과적합을 더 잘 피하면서 보다 쉽게 사용될 수도 있다는 가능성과 CNN과 결합하여 좋은 일반화 성능을 이끌어 낼 수도 있다는 가능성을 확인해보았다.

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>