@senspond
>
ResNet 이해하기 - Residual Learning, Bottleneck Block
ResNet 이 무엇인지 알아보고 Residual Learning, Bottleneck Block 에 대해서 정리해 본 글입니다.
 ImageNet Benchmark (Image Classification) | Papers With Code
ImageNet Benchmark (Image Classification) | Papers With Code
ImageNet 은 대표적인 파블릭 대규모 데이터셋으로 ILSVRC (ImageNet Large Scale Visual Recognition Challenge) 이고 실제 대회에서 사용되었던 데이터 셋으로 컴퓨터비전분야 논문에서 많이 나오는 데이터셋이기도 하다. 이미지가 1,000만 개가 넘는다. 학습데이터 셋 용량이 135GB, 검증 데이터넷 용량이 6GB에 달한다.
참고로 현재 2024년 ImageNet 이미지 분류에 1등 모델은 Vision Transformer이다.
ResNet을 설명하려면 2015년 시점으로 돌아가 살펴 보아야 한다. 당시 ResNet은 기존 Plain CNN 방식의 GoogleNet, VGGNet 같은 모델 보다 훨씬 더 깊은 네트워크로 쌓으면서 성능을 크게 끌어올리며 혁명적인 사건이 되었다. 당시 기준으로 ResNet은 ImageNet 이미지 분류, COCO 객체 검출 및 세그먼트 작업 등 각종 대회에서 1등을 하며 유명세를 타게 된다.
이 사건이 혁명적이였던 것은 단순히 성능을 끌어올린 것을 넘어서 RestNet-152는 무려 네트워크를 152층이나 쌓으면서 그동안 CNN모델의 고질병이었던 네트워크를 깊게 쌓을 수록 기울기 소실(Gradient Vanishing) 과 같은 문제를 해결 했기 때문이다.
ResNet 이 등장하게 된 배경
그동안 CNN모델의 성능을 끌어올리려는 시도가 다양하게 연구되었다. 커널 사이즈를 튜닝하거나 Dropout, Weight Decay와 같은 여러가지 기법을 사용했지만 한계점에 도달했다. 특히 깊은 네트워크를 쌓게 되면 기울기 소실(Gradient Vanishing) 과 같은 문제가 발생하기가 쉽고 오히려 성능이 저하되는 문제 등이 발생했다.
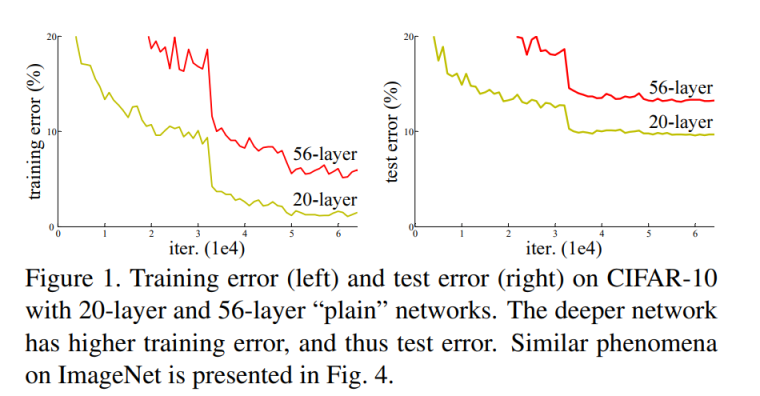 (20-layer 보다 56-layer가 오류가 더 높은 실험결과 : https://arxiv.org/pdf/1512.03385.pdf)
(20-layer 보다 56-layer가 오류가 더 높은 실험결과 : https://arxiv.org/pdf/1512.03385.pdf)
딥러닝에서 이런현상이 일어나는 이유는 무엇일까?
네트워크에서 층이 깊어지면 깊어질 수록 많은 피쳐를 추출하게 되는데, 문제는 더 많은 층을 거치게 될 수록 원본 이미지 데이터를 손실해가며 뻘짓을 하기 시작한다. 예를 들어 어떤 이미지에 대해 각층마다 피쳐를 추출해내는데, 층이 깊어지면 그레디언트손실 문제로 인해 원본 이미지와 멀어진 이미지를 가지고 피쳐로 뽑고 있는 뻘짓이 이루어지는 현상이 된다는 것이다. 그러니까 모델을 학습을 시키면서 원본 이미지는 이거였어! 이거였다고! 계속해서 상기시켜주면 성능이 좋아지지 않을까 하는 생각에서 출발하게 됬다고 볼 수가 있다. 이것은 LSTM블록처럼 과거 상태를 계속 상기시켜주는 아이디어와도 비슷하다.
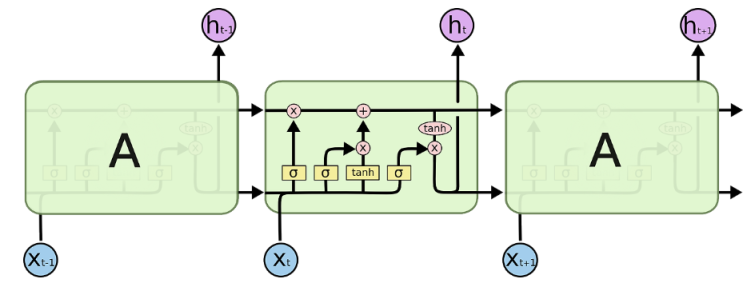
LSTM은 RNN이 가지고 있던 input과 output의 시간 격차가 길어질 수록(long-term dependencies) 기울기 소실(Gradient Vanishing) 이 발생하고 학습이 어려워 지는 상황을 극복할 수 있게 해주었다.
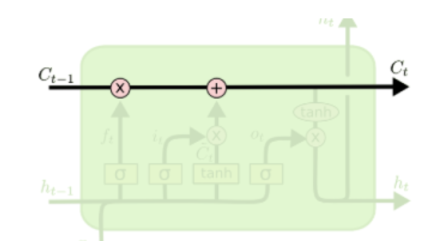
LSTM의 핵심은 모듈 그림에서 수평으로 그어진 윗 선에 해당한다. 일종의 고속도로와도 같다. 이전 시점의 cell state를 다음 시점으로 전달해주는데 각 gate의 결과를 더함으로써 진행하게 된다.
ResNet의 아이디어
Residual Learning
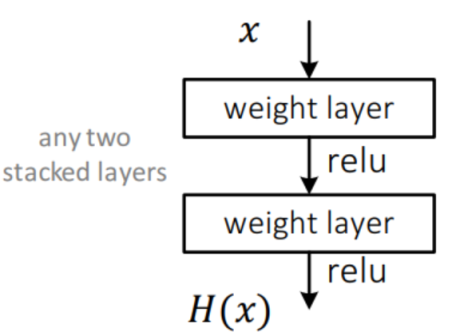
일반적인 CNN의 구조는 위와 같다. x가 weight layer을 지나 활성함수 Relu를 통과하고 나온 H(x)를 최적화하는 것을 목표로 가중치를 학습 시키게 된다. 하지만 RestNet에서는 다른 방식을 제안한다.
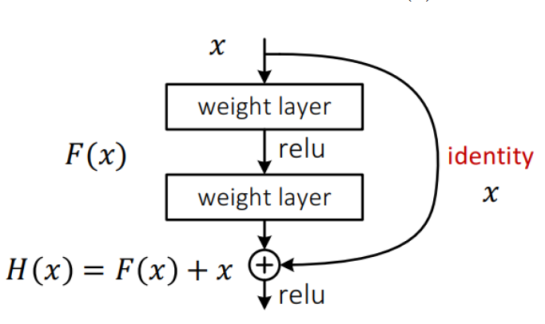 입력으로 들어온 x를 weight layer을 통해 아래로 흐르게 하는 부분을 F(x)라고 한다면,
입력으로 들어온 x를 weight layer을 통해 아래로 흐르게 하는 부분을 F(x)라고 한다면,
H(x) = F(x) + h(x) 가 되고, identity function으로 h(x)=x 가 되어 H(x) = F(x) + x 가 된다.
그리고 이렇게 나온 출력 H(x)는 다음 레이어의 잇풋으로 들어간다. 이러한 블록은 잔치블록(Residual Block)이라고 하는데, 이러한 구조로 쌓아서 F(x) := H(x) − x 즉, 잔차가 0에 근사하도록 가중치를 학습 시키자는 것이다. 즉 층이 깊어져도 원래 이미지가 어떠했는지 좀 더 오랫동안 유지하자는 것에 있다. 학습과정으로 살펴보면 역전파 알고리즘으로 그레디언트를 전파할 때 shortcut(skip connection) 일종의 지름길을 제공하게 되어 좀더 그레디언트를 잘 전파 할 수 있게 된다.
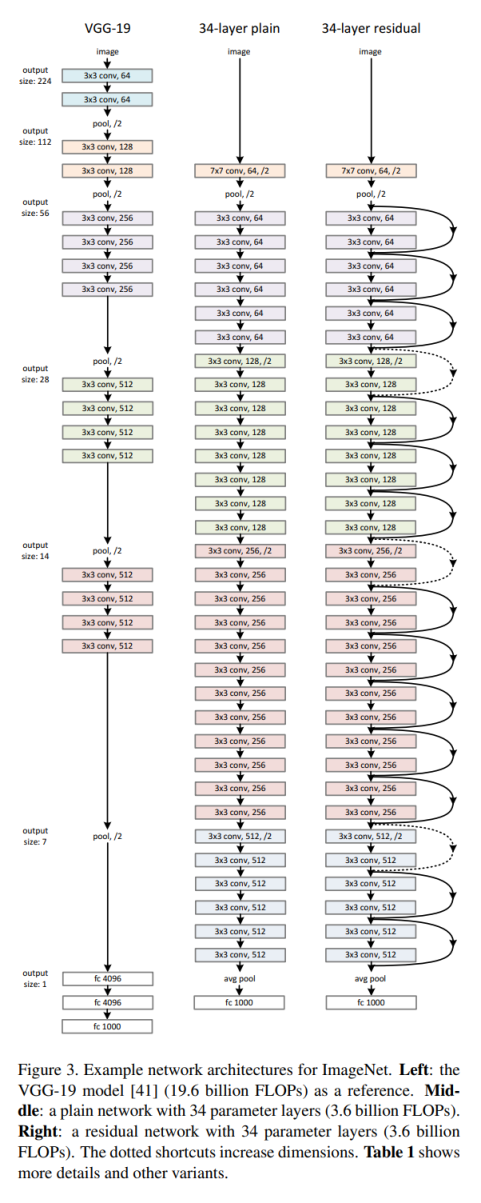
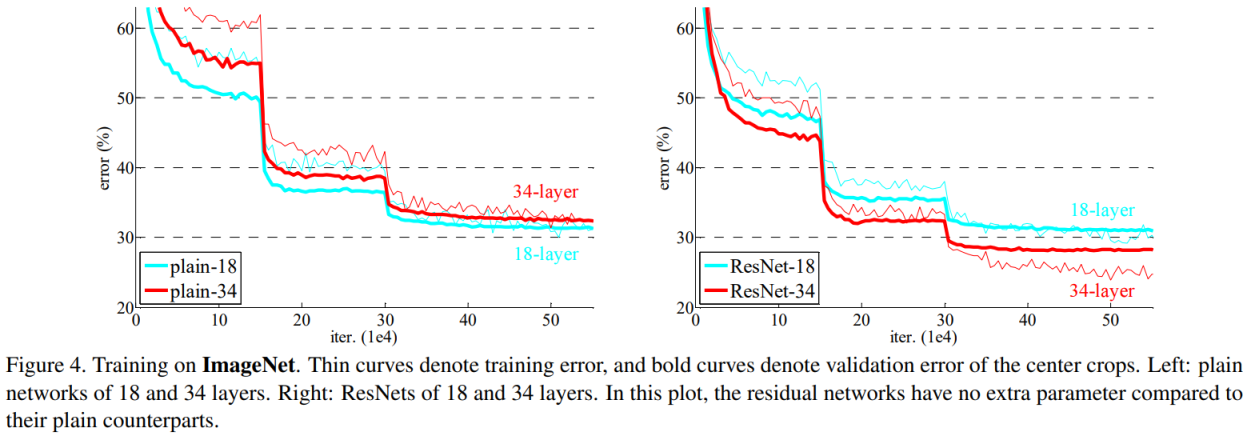
논문에서는 plain 방식으로 층을 쌓았을 때 층을 일정 깊이 이상 쌓게 되면 오히려 오류가 증가하지만, 이러한 방식으로 쌓게 되면 오류가 감소하는 것을 Imagenet 18층과 34층 비교를 통해 결과를 제시하였다..
그런데 이러한 방식으로 더 깊은 네트워크를 쌓게 되었을 때 또 다시 문제점이 발생한다. 이러한 방식은 층이 깊어질 수록 연산량이 기하급수적으로 증가하기 때문이다. 아무리 성능이 좋아도 학습을 시키는데 너무 오래 걸린다면 현실적으로 적용하기 어려운 모델이기 때문이다. 이 문제를 해결하기 위해 다음과 같은 개념이 등장한다.
Bottleneck Block
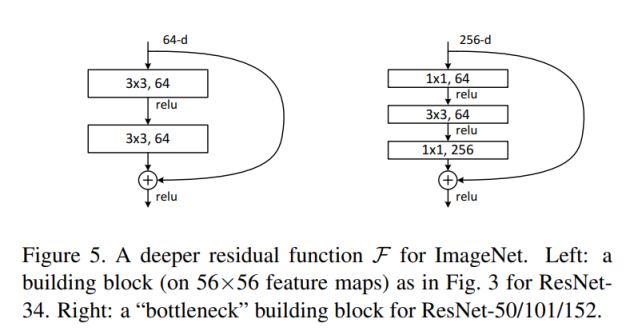
좌측이 일반적인 standard residual block 을 적용한 것이고 우측이 bottleneck block을 적용한 그림이다.
3x3 Convolution은 1x1 Convolution 보다 9배나 연산량이 많기 때문에, 1x1 Convolution을 통해 채널을 줄인 후에 3x3 Convolution에서 특성을 추출하며 다시 채널을 키운다. 좌측보다 레이어는 한개 더 쌓게 되었지만 결과적으로 총 파라미터 수가 좌측에 비해서 대폭 감소하게 되면서 연산 속도가 증가하게 된다.
ResNet의 구성
ImageNet을 기준으로 18레이어 부터 152레이어까지 쌓는 방법이 예시로 나와있다.

사전 학습 ResNet이용
keras 사전 학습된 ResNet50 이용해 Cifar10 이미지 분류
tf.keras.applications.ResNet50 | TensorFlow v2.16.1
케라스 API를 사용하면 Imagenet 사전 학습된 가중치를 가지고 있는 ResNet을 쉽게 사용할 수 있다.
import tensorflow as tf
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from matplotlib import pyplot as plt
(training_images, training_labels) , (validation_images, validation_labels) = tf.keras.datasets.cifar10.load_data()
def preprocess_image_input(input_images):
input_images = input_images.astype('float32')
output_ims = tf.keras.applications.resnet50.preprocess_input(input_images)
return output_ims
train_X = preprocess_image_input(training_images)
valid_X = preprocess_image_input(validation_images)
'''
Feature Extraction is performed by ResNet50 pretrained on imagenet weights.
Input size is 224 x 224.
'''
def feature_extractor(inputs):
feature_extractor = tf.keras.applications.resnet.ResNet50(input_shape=(224, 224, 3),
include_top=False,
weights='imagenet')(inputs)
return feature_extractor
'''
Defines final dense layers and subsequent softmax layer for classification.
'''
def classifier(inputs):
x = tf.keras.layers.GlobalAveragePooling2D()(inputs)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(1024, activation="relu")(x)
x = tf.keras.layers.Dense(512, activation="relu")(x)
x = tf.keras.layers.Dense(10, activation="softmax", name="classification")(x)
return x
'''
Since input image size is (32 x 32), first upsample the image by factor of (7x7) to transform it to (224 x 224)
Connect the feature extraction and "classifier" layers to build the model.
'''
def final_model(inputs):
resize = tf.keras.layers.UpSampling2D(size=(7,7))(inputs)
resnet_feature_extractor = feature_extractor(resize)
classification_output = classifier(resnet_feature_extractor)
return classification_output
'''
Define the model and compile it.
Use Stochastic Gradient Descent as the optimizer.
Use Sparse Categorical CrossEntropy as the loss function.
'''
def define_compile_model():
inputs = tf.keras.layers.Input(shape=(32,32,3))
classification_output = final_model(inputs)
model = tf.keras.Model(inputs=inputs, outputs = classification_output)
model.compile(optimizer='SGD',
loss='sparse_categorical_crossentropy',
metrics = ['accuracy'])
return model
model = define_compile_model()
model.summary()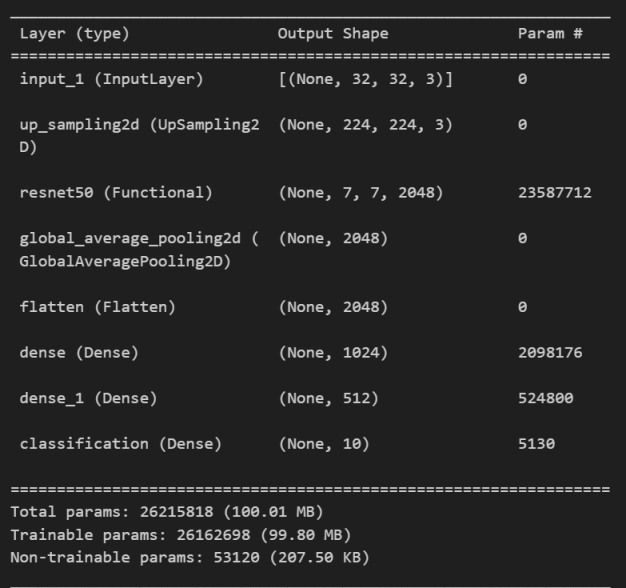
Cifar10 이미지 데이터셋으로 사전 학습된 ResNet50을 3회 정도 학습하니 테스트 정확도가 95% 정도 나왔다.
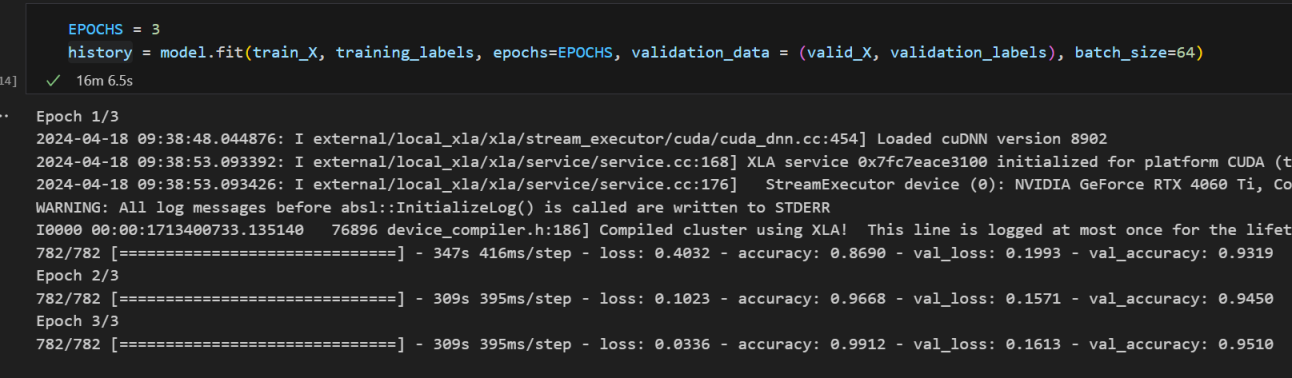

직접 수동으로 구현한 것보다 더 적은 학습 만으로 좋은 성능이 나와 주었다. 다음 시간에는 keras와 pytorch로 ResNet을 밑바닥부터 구현해본 과정을 정리해보기로 하고 이 글에서 부족했던 부분을 좀 더 정리해보기로 한다.
pytorch
from torchvision.models import ResNet, ResNet50_Weights
# RegNet(pretrained=True, weights=ResNet50_Weights.IMAGENET1K_V1) old weights
ResNet(pretrained=True, weights=ResNet50_Weights.IMAGENET1K_V2)파이토치에서는 위와 같이 사용할 수가 있다.
참고자료
[ 논문 Deep Residual Learning for Image Recognition ] : https://arxiv.org/pdf/1512.03385.pdf

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>