@senspond
>
Ollama를 통해 local 컴퓨터 환경에서 LLM(Large Language Model) 구동하기
Ollama를 설치하고 local 컴퓨터 환경에서 LLM(Large Language Model) 구동하는 방법을 자세하게 정리한 글입니다.
용어
LLM 이란?
LLM은 Large Language Model의 약자로, 방대한 양의 텍스트 데이터를 기반으로 학습된 인공 지능(AI) 모델입니다. 텍스트 생성, 번역, 요약, 질의응답 등 다양한 자연어 처리(NLP) 작업을 수행할 수 있습니다. ChatGPT 의 등장으로 일반인에게도 많은 관심을 받고 있습니다.
Ollama란?
Llama 2, Llama 3, Phi, Mistral, Solar와 같은 대규모 언어 모델(LLM)을 로컬 환경에서 실행할 수 있도록 도와주는 도구입니다.
ollama를 통해 다양한 오픈소스 LLM 모델들을 설치하고 구동할 수 있습니다.
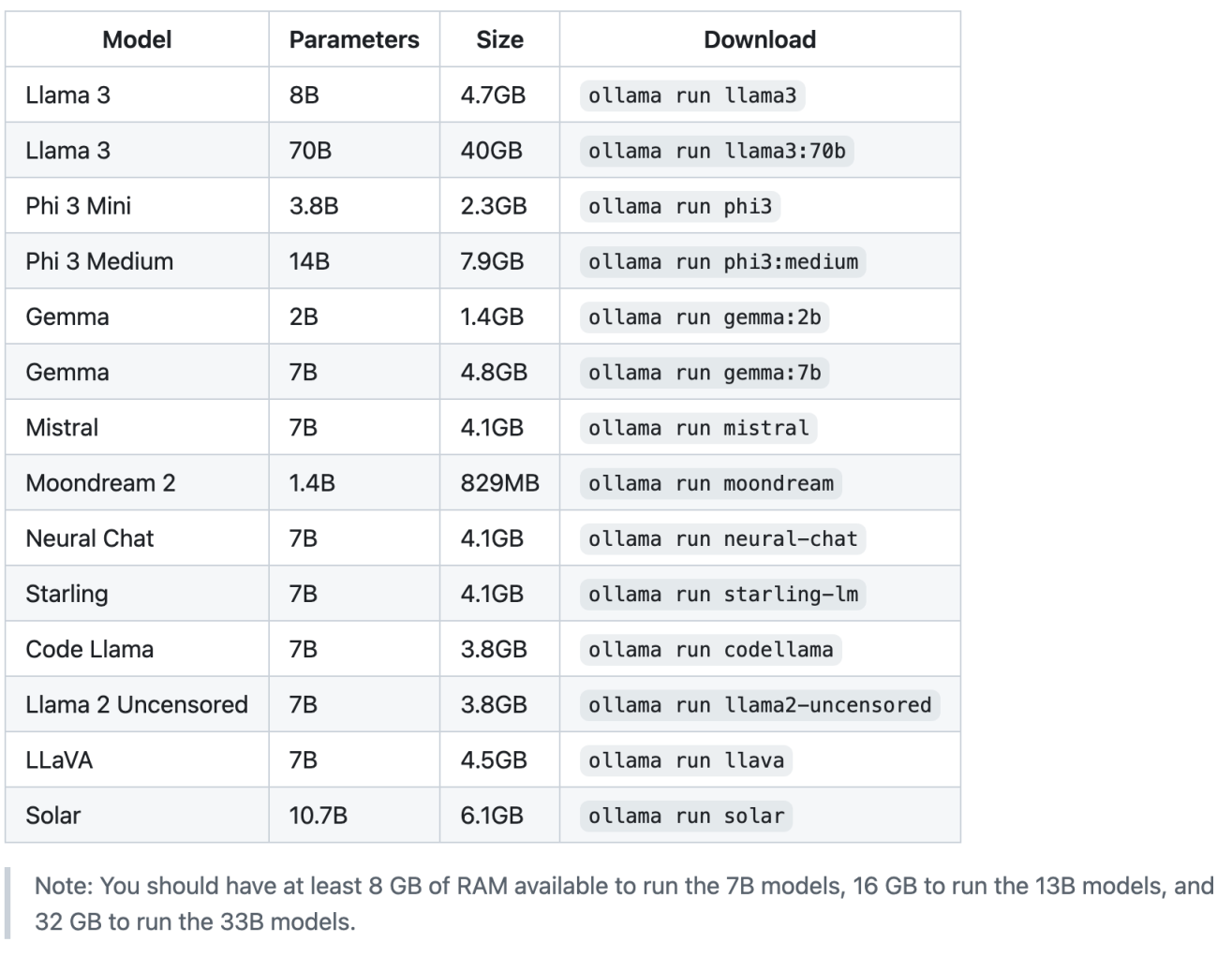
이미지 출처 : https://github.com/ollama/ollama?tab=readme-ov-file#model-library
Ollama 설치 방법
공식 홈페이지 ( https://ollama.com/ ) 에서 자신의 컴퓨터 환경에 맞는 OS로 설치파일을 다운받아 실행합니다.
macOS/ Linux / Windows
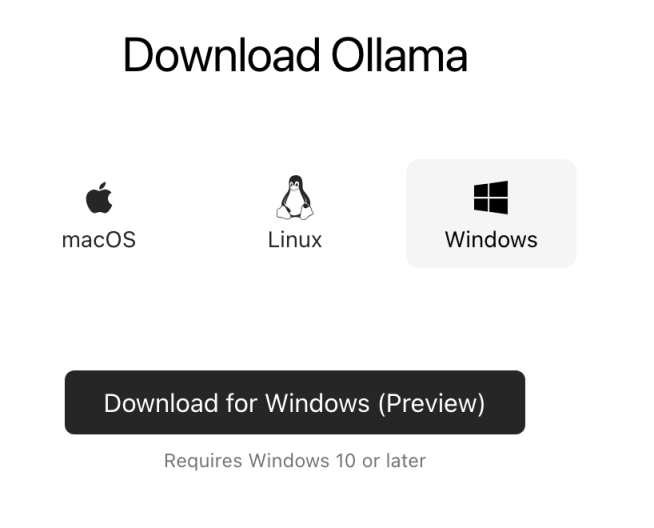
현재 이 글을 작성하는 2024년 6월 3일 기준으로 Windows는 프리뷰 버전만 지원합니다.
Docker
공식 Docker 이미지 ollama/ollama를 사용할 수 있습니다.
https://hub.docker.com/r/ollama/ollama
CPU Only
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaNvidia GPU
Configure the repository
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
Install the NVIDIA Container Toolkit packages
sudo apt-get install -y nvidia-container-toolkitOllama 사용법
실행명령어
ollama 명령어 | 실행 |
ollama serve | ollama 시작 |
ollama pull [model] | [model] 설치 |
ollama run [model] | [model] 실행 |
ollama list | 모델 리스트 출력 |
ollama rm [model] | [model] 삭제 |
/bye | [model] 실행 종료 |
/? | 도움말 출력 |
/show info | 현재 실행 모델 정보 출력 |
/load [model] | [model] 불러오기 |
/save [model] | [model] 저장하기 |
모델 커스터마이징
Ollama 라이브러리의 모델은 프롬프트로 커스터마이징할 수 있습니다. 예를 들어 llama3 모델을 수정하려면:
모델 다운로드
ollama pull llama3Modelfile 생성
FROM gemma
# 온도 설정 (높을수록 창의적)
PARAMETER temperature 1
# 시스템 메시지 설정
SYSTEM """
당신은 나의 충성스러운 비서입니다. 사장님에게 보고하듯이 대답해주세요.
"""모델 생성 및 실행
ollama create mario -f ./Modelfile
ollama run marioAPI 로 접근
generate
curl http://localhost:11434/api/generate -d '{
"model": "gemma",
"prompt": "딥러닝은 무엇인가요?"
}'chat
curl http://localhost:11434/api/chat -d '{
"model": "gemma",
"messages": [
{"role": "user", "content": "점심에 뭐 먹을까요?"}
]
}'LangChain 으로 Ollama 사용하기
사용방법
먼저 Ollama가 자신의 컴퓨터에 설치되어 있어야 합니다. 그리고 파이썬 환경에서 langchain과 langchain_community를 설치합니다.
pip install langchain
pip install langchain_community
그리고 langchain_community 패키지의 chat_models 모듈의 ChatOllama 라는 클래스를 통해 ollama 모델에 접근 할 수가 있는데요.
예시코드
my_llm.py
import argparse
from langchain_community.chat_models import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
def request_llm(message):
llm = ChatOllama(
# model="EEVE-Korean-10.8B:latest",
# model="gemma:7b",
model="llama3",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
)
# prompt = ChatPromptTemplate.from_template()
prompt = ChatPromptTemplate.from_messages(
[
("system", """Please answer briefly and sweetly in a cute tone."""),
("human", "{message}")
])
chain = prompt | llm
return chain.invoke({"message": message})
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-m", default="hi")
args = parser.parse_args()
request_llm(args.m)python my_llm.py -m "hello, how are you?"
Ollama와 LangChain으로 초간단하게 ChatBot을 만들기
얼마전 제 유튜브 채널에 업로드 해봤는데, 참고하세요.

안녕하세요. Red, Green, Blue 가 만나 새로운 세상을 만들어 나가겠다는 이상을 가진 개발자의 개인공간입니다.
댓글 ( 0 )
카테고리내 관련 게시글
현재글에서 작성자가 발행한 같은 카테고리내 이전, 다음 글들을 보여줍니다
@senspond
>